Statistiques Big Data : Nombre de Données Produites par Jour
Découvrez les statistiques clés du big data pour rester compétitif en 2026. Apprenez à les utiliser efficacement. Lisez l'article pour en savoir plus !
Le Big Data est devenu un pilier incontournable de la transformation numérique.
La collecte et l’analyse de volumes massifs de données structurées et non structurées bouleversent toutes les industries, poussant les entreprises et institutions à maîtriser ces flux pour rester compétitives.
L'analyse du big data permet aux entreprises d'exploiter de grands volumes de données structurées et non structurées pour extraire des modèles, des tendances et des prévisions.
Chiffres clés et tendances majeures
Les chiffres illustrent à quel point le volume de données explose, impactant directement les marchés et les usages.
🌐 Chiffres clés et tendances majeures du Big Data en 2026
📊 Indicateur
📈 Statistique 2026
💡 Contexte et impact
Volume mondial de données
≈ 181 à 182 zettabytes (182 milliards de téraoctets)
Explosion exponentielle du stockage et besoin accru en solutions cloud et IA
Croissance du marché Big Data
$90 à $244 milliards — croissance annuelle entre 12 et 15%
Marché tiré par l’IA générative, les data lakes et les solutions d’analyse prédictive
Appareils IoT générant des données
+75 milliards d’appareils connectés
Multiplication des flux temps réel dans la logistique, la santé et les villes intelligentes
Données créées par le secteur santé
≈ 2 314 exaoctets/an
Principal contributeur mondial, porté par la télémédecine et les dispositifs médicaux connectés
Adoption du Big Data en entreprise
61% des sociétés mondiales utilisent des solutions Big Data
Croissance soutenue dans les PME via les outils SaaS et les solutions no-code analytiques
Ces données traduisent l’ampleur sans précédent de la croissance des données massives, créée par l’internet des objets, le mobile, les transactions numériques, et les interactions en temps réel.
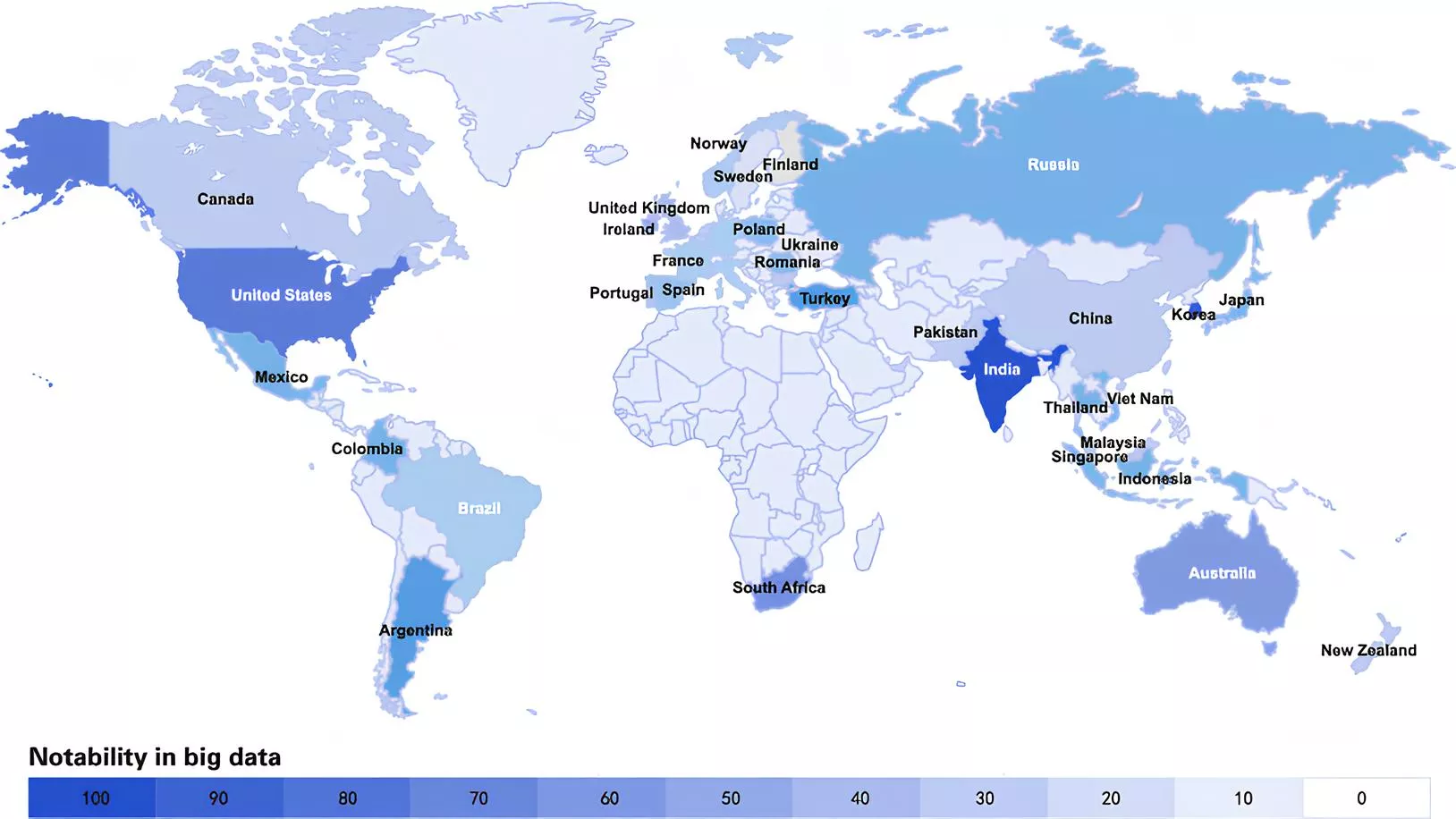
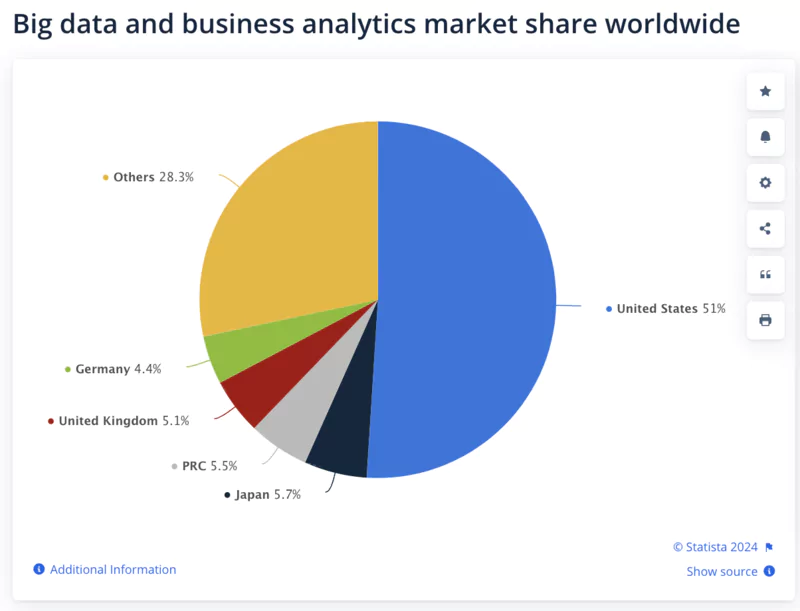
Classement des pays qui produisent le plus de Big Data
La production de Big Data est dominée par plusieurs pays, grâce à leurs infrastructures technologiques et leurs populations connectées.
Voici une revue du classement basé sur les chiffres en date d'aujourd'hui :
États-Unis : Environ 40% de la production mondiale de données, avec des géants comme Google, Amazon, Meta, Microsoft et IBM.
Chine : Contribue à 20% de la production mondiale, grâce à des entreprises comme Alibaba, Tencent et Baidu.
Inde : Produit environ 12% des données mondiales, avec des leaders comme Tata Consultancy Services et Infosys.
Union Européenne : Environ 15% de la production mondiale, principalement de pays comme l'Allemagne, la France et le Royaume-Uni.
Japon : Responsable d'environ 7% de la production mondiale, avec des entreprises telles que Sony, Panasonic et Toyota.
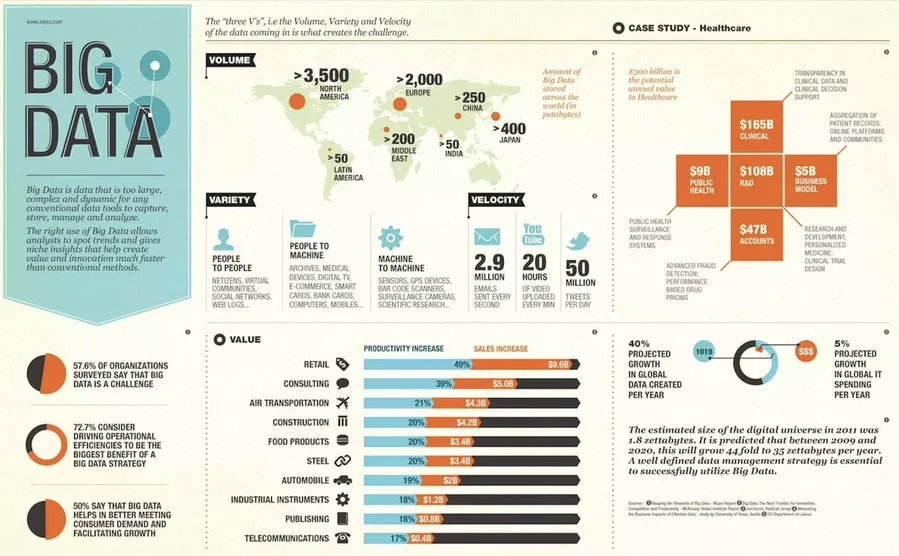
Enjeux liés à l’explosion des données
La croissance exponentielle des flux de données soulève des défis majeurs :
Stockage et gestion : gérer un volume gigantesque de données hétérogènes (structurées, non structurées).
Qualité des données : assurer leur fiabilité, traiter les données manquantes, anormales ou bruitées.
Analyse en temps réel : les entreprises veulent des réponses instantanées (finance, e-commerce, santé).
Sécurité et éthique : protéger les données sensibles tout en respectant la vie privée.
Compétences techniques : besoins croissants en data scientists maîtrisant les méthodes avancées.
Cette importance stratégique pousse à innover sur le traitement des données aussi bien au niveau informatique que statistique, l'objectif étant de transformer le Big Data en un avantage compétitif.
Plus des trois quarts des personnes interrogées ont déclaré qu'elles stimulaient l'innovation grâce aux données, tandis que la moitié considérait que leurs entreprises étaient compétitives grâce aux données et à l'analyse.
Grâce aux algorithmes de recommandation nourris au Big Data, Netflix économise 1 milliard de dollars par an en fidélisation client.
Les entreprises "data driven" ont 23 fois plus de chances de gagner des clients.
72% des dirigeants du secteur manufacturier comptent sur l'analyse Big Data pour booster leur productivité.
83% des utilisateurs TikTok indonésiens ont une meilleure opinion des marques automobile après les avoir vues sur l'app.
Ces exemples concrets montrent comment le Big Data permet de mieux comprendre et servir leurs clients, d'optimiser leurs opérations et d'innover. Le marketing, la finance, la santé, les médias... aucun secteur n'échappe à cette révolution.
Méthodes statistiques
Les données nécessitent des approches statistiques adaptées à la taille et à la complexité des données, voici leurs paramètres :
📐 Méthodes statistiques indispensables pour analyser le Big Data (2026)
📊 Méthode
🔧 Usage clé
📝 Exemple d’application
Statistiques descriptives
Synthétiser les données : moyenne, médiane, variance, écart-type
Profilage client ou analyse de tendances d’achat
Modèles de régression
Analyser les relations entre variables et prédire les comportements
Prévision des ventes, estimation du risque client
Analyse dimensionnelle
Réduire la complexité des jeux de données via ACP, t-SNE, UMAP
Visualisation de données multidimensionnelles, simplification de modèles IA
Test d’hypothèses
Comparer des groupes ou valider des différences statistiques
Analyse d’efficacité d’une campagne marketing (t-Test, ANOVA)
Méthodes d’échantillonnage
Travailler sur des sous-ensembles représentatifs (simple, stratifié, cluster)
Analyses rapides sur des flux massifs de données
Algorithmes de machine learning
Apprentissage supervisé/non supervisé pour classification, prédiction et clustering
Détection de fraude, segmentation client, maintenance prédictive
Traitement parallèle
Utiliser des frameworks comme Hadoop ou Spark pour gérer le volume et la vitesse
Analyse en temps réel de données issues de capteurs IoT
L’association des méthodes statistiques classiques et des outils d’analyse avancée permet de dépasser les limites des méthodes traditionnelles, souvent inadaptées au très grand volume de données.
Comment les statistiques exploitent-elles le Big Data ?
L’exploitation statistique des données massives génère des insights opérationnels déterminants :
Santé : analyse de millions de dossiers pour déceler des tendances épidémiologiques ou personnaliser des traitements.
Finance : détection anticipée de fraudes via analyses comportementales et algorithmes prédictifs.
Logistique : optimisation des itinéraires en temps réel grâce à la modélisation statistique des flux et aléas.
Marketing : segmentation fine des clients, anticipation des besoins par modélisation des comportements d’achat.
Ces applications démontrent l’importance cruciale de la data science dans la prise de décision optimisée, en transformant des données brutes en valeur actionable.
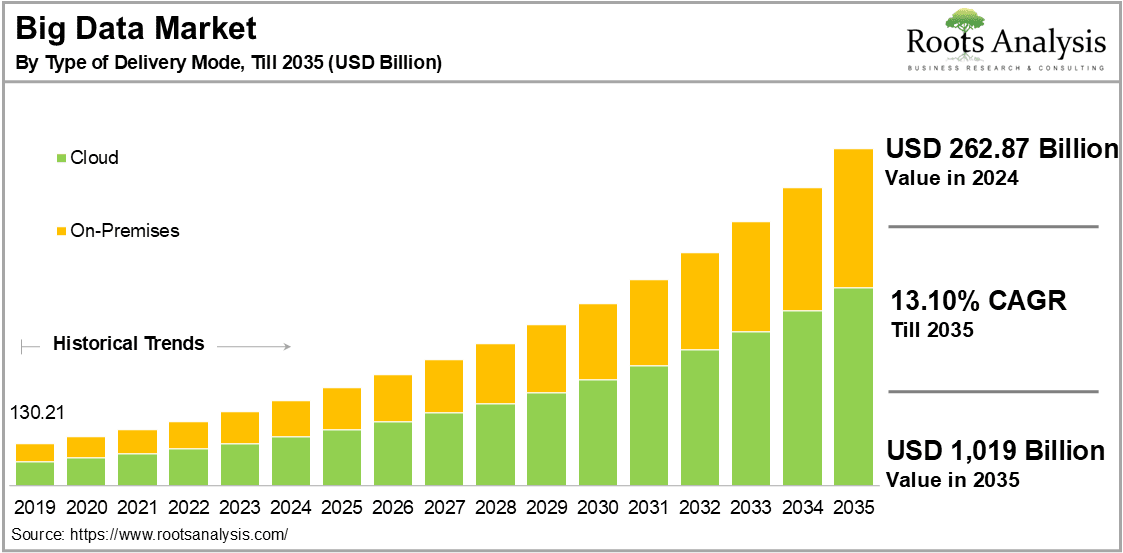
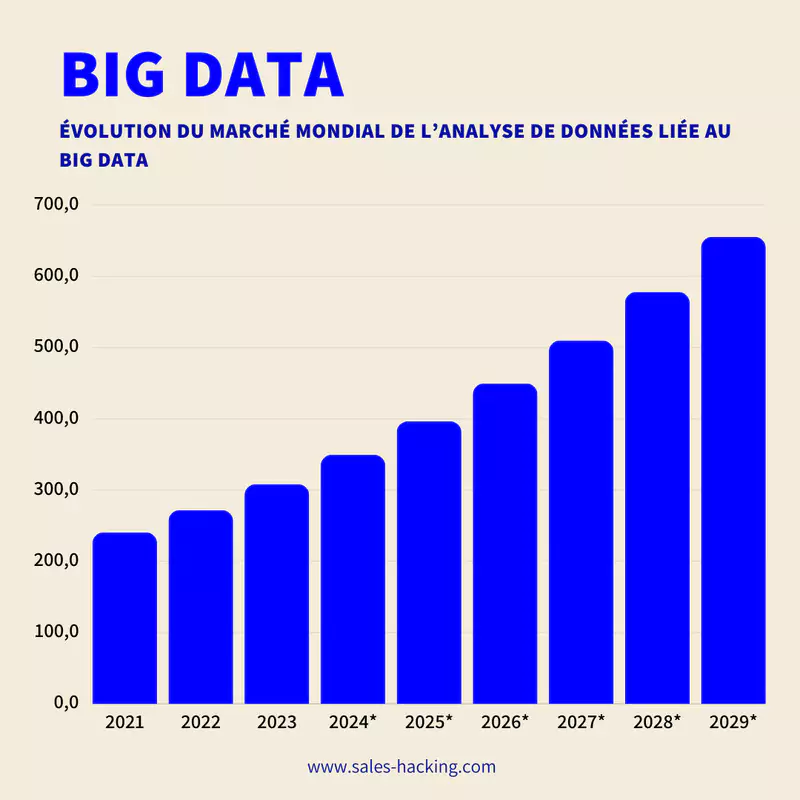
Un Marché en Plein Boom
Dans son histoire récente, en 2021, la valeur du marché mondial de l'analyse des données a dépassé les 240 milliards de dollars américains.
Une hausse notable est anticipée, avec une valeur de marché prévue de plus de 655 milliards de dollars d'ici 2029, soulignant l'essor et l'importance croissante des enjeux ou problèmes de l'analyse des données dans l'économie mondiale.
Le marché mondial du Big Data et de l'analytique pèse 274 milliards de dollars en 2024.
Il devrait atteindre 655 milliards de dollars en 2029, soit une hausse annuelle moyenne de +19%.
Le marché de l'analyse Big Data dans le secteur bancaire devrait atteindre 62 milliards de dollars en 2026.
Dans la recherche scientifique pour la santé, ce marché pèsera 68 milliards en 2026, soit 4 fois plus qu'en 2018.
97% des sociétés investissent activement dans le Big Data et l'IA.
Ces chiffres démontrent que les sociétés ont bien compris l'enjeu stratégique du Big Data.
Elles y consacrent des budgets colossaux (et ont raison) pour développer des capacités d'analyse et des modèles mathématiques toujours plus poussées et en retirer un avantage de manière concurrentielle.
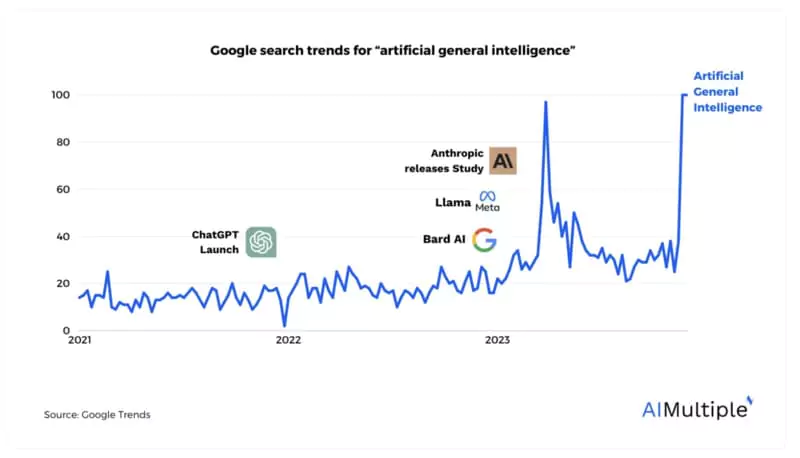
Corrélation du big data et de l'intelligence artificielle
Le Big Data et l'intelligence artificielle (IA) sont deux forces transformatrices de notre époque. Mais c'est leur convergence qui promet de bouleverser nos sociétés dans les décennies à venir.
Le Big Data est en effet le carburant indispensable pour nourrir des systèmes d'IA toujours plus performants et autonomes.
Selon une étude de 2022, il y a 50% de chances que l'AGI (intelligence artificielle générale) soit atteinte d'ici 2059.
Des experts comme Geoffrey Hinton et Elon Musk évoquent même une échéance entre 5 et 20 ans.
Pour réaliser ce saut vers l'AGI, les chercheurs misent sur une nouvelle génération de modèles d'IA alimentés par des quantités pharaoniques de données.
Au-delà de l'aspect quantitatif, la route vers l'AGI passera aussi par des innovations algorithmiques :
Apprentissage non supervisé, raisonnement symbolique, architectures neuronales bio-inspirées, apprentissage par renforcement...
Cicero (Meta) : module de langage + raisonnement stratégique + mémoire à long terme. Performe aussi bien qu'un humain au jeu Diplomacy.
Gato et Flamingo (DeepMind) : entraînés sur texte, images et interactions. Capacités d'adaptation remarquables à des tâches variées.
Taille du marché de l'AI parallèle à celui du Big Data
Défis et OpportunitésLa perspective d'une IA aux capacités surhumaines, nourrie par les flots du Big Data, est à la fois fascinante et inquiétante.
Opportunités : résoudre des défis majeurs comme le changement climatique, les maladies, la pauvreté...
Défis : questions existentielles sur notre place dans l'univers, risques d'une IA incontrôlable...
Une chose est sûre : la convergence du Big Data et de l'IA nous promet des bouleversements inouïs.
À nous d'orienter et d'encadrer dès maintenant cette révolution technologique pour qu'elle profite au plus grand nombre.
L'avènement de l'AGI n'est plus de la science-fiction, c'est un horizon qui se rapproche à grands pas. Faisons en sorte que ce nouveau chapitre de l'aventure humaine soit porteur d'espoir et de progrès !
Entreprises dans le monde
Dans l'univers du Big Data, certaines entreprises se distinguent par la quantité massive qu'elles génèrent et collectent.
Voici un classement des entreprises qui produisent le plus de données au monde chaque jour
Classement
Entreprise
Volume de données produites chaque jour (en pétaoctets)
1
Google
10 000
2
IBM
1 000
3
Netflix
500
4
Facebook
4
5
Dropbox
3,6
6
Amazon
2
7
Spotify
1,8
8
Airbnb
1
9
Uber
0,1
10
Apple
0,05
11
Microsoft
0,001
12
Twitter
0,005
13
Alibaba
0,0002
14
Baidu
0,0001
15
eBay
0,00005
Grâce à leur envergure mondiale et à leur large base d'utilisateurs, tous sont devenues des acteurs majeurs dans cet écosystème.
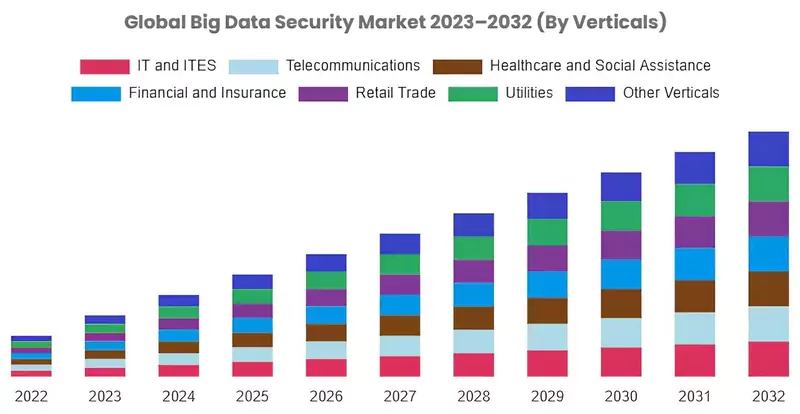
Défis du traitement statistique du Big Data
Donnée et Sécurité : chiffre de référence de la hausse exponentielle prévue de 2023 à 2032
Traitant d’ensembles de données colossaux et variés, le Big Data introduit plusieurs défis uniques côté statistique :
Hétérogénéité : diversité des formats et sources complique les modèles classiques.
Bruit et corrélations factices : risque d'erreurs statistiques dues à des coïncidences dans les données volumineuses.
Dimensionnalité élevée : trop de variables entraîne un surapprentissage et des biais.
Biais endogènes : corrélations non causales qui faussent les conclusions.
Équilibre précision/rapidité : trouver des méthodes à la fois fiables et suffisamment rapides.
Pour répondre, de nouvelles approches régulières, des méthodes de sélection de variables et des techniques de validation robustes sont indispensables.
Tableau comparatif : Méthodes statistiques vs défis du Big Data
📊 Méthodes statistiques vs défis du Big Data (2026)
⚠️ Défi / Problème
✔️ Solutions & Méthodes
🛠️ Outils / Techniques
Hétérogénéité des données
– Pré-traitement et nettoyage des données
– Normalisation / standardisation
– Harmonisation des schémas et formats
– K-anonymity, l-diversity
– DP-SGD, ajout de bruit calibré
– Catalogues de données, RBAC/ABAC
Vers un futur de plus en plus "Data-Driven"
En 2026, la vidéo représente 65,93 % du volume de données total sur Internet, marquant une hausse de 24 % par rapport à 2023.
Ce chiffre englobe tout comme la télévision, le streaming et les téléchargements vidéo.
Les secteurs des marketplaces, des jeux et des réseaux sociaux ont chacun contribué à plus de 5 % du trafic, confirmant la vidéo comme principale composante de l’activité en ligne
D’ici 2026, 30% des données dans le monde seront traitées en temps réel.
Le marché de l’”Analytics-as-a-Service“ (AaaS) atteindra 69 milliards de dollars en 2028.
Le nombre d’objets connectés, principaux pourvoyeurs, bondira à 29 milliards en 2030.
Une chose est sûre : la déferlante de bases de données est loin de refluer.
Pour rester compétitives, les entreprises devront plus que jamais miser sur les technologies de pointe comme l’intelligence artificielle, l’informatique quantique, l’Edge computing et d’autres innovations technologiques pour optimiser la gestion du big data.
Conclusion
Les statistiques Big Data combinent de puissantes capacités de traitement de données massives avec des méthodes analytiques avancées.
Les chiffres dévoilent une explosion des volumes et une adoption massive par les entreprises, mais aussi des défis techniques et méthodologiques à relever pour exploiter pleinement ce potentiel.
Une approche statistique adaptée, associée à des technologies innovantes, permet de transformer ces montagnes de données en informations stratégiques exploitables. Les décideurs et professionnels doivent donc comprendre ces enjeux et se former aux méthodes nécessaires.
Si vous souhaitez bénéficier pleinement de la révolution Big Data, il est temps de maîtriser ces statistiques et méthodes qui transforment la donnée en moteur d’innovation et de performance métier.
Liste des statistiques clés du Big Data
Volume des données créées
En 2023, le nombre de données produites par jour est énorme, chaque minute internet voit 241 millions d’e-mails envoyés, illustrant l’intensité de la communication numérique et la recherche d'informations en ligne.
Le streaming vidéo, avec Netflix et ses 209 millions d’abonnés, domine la consommation de médias en ligne, bénéficiant d’infrastructures numériques améliorées.
Les apps de messagerie comme WhatsApp, Facebook Messenger et Telegram, populaires pour leurs services étendus, incluant photos, vidéos, et appels gratuits, redéfinissent la communication globale.
Une minute sur Internet : connectivité et contenu en effervescence - Source : Statista
En 2024, le volume total de données numériques créées dans le monde atteindra 147 zetta-octets, contre seulement une quantité de données de 9 zetta-octets en 2013.
1 zettaoctet = 1 trillion de gigaoctets, soit 1 suivi de 21 zéros !
Chaque être humain génère en moyenne 1,7 mégaoctet de données par seconde.
80 à 90% de ces données sont non structurées (images, vidéos, audios, réseaux sociaux…).
Pour télécharger l’intégralité des données présentes sur Internet, il faudrait plus de 180 millions d’années à un individu.
Ces chiffres donnent le vertige et illustrent le défi titanesque que représente le traitement de telles masses de données. Mais ils recèlent aussi d’immenses opportunités pour les entreprises capables d’en extraire des insights actionnables. Tout cela montre l'étendue complète des données générées et l'importance croissante de leur analyse.
Solutions matérielles pour le stockage
Voici un aperçu des principales solutions matérielles utilisées pour le stockage, ainsi que quelques chiffres clés et statistiques :
Système de fichiers distribués
Les systèmes de fichiers distribués, tels que Hadoop Distributed File System (HDFS) et Google File System (GFS), sont conçus pour stocker et gérer des données massives sur des clusters de serveurs.
Ils répartissent les informations sur plusieurs formes de nœuds, assurant ainsi une haute disponibilité et une tolérance aux pannes.
HDFS est utilisé par plus de 70 % des sociétés ayant adopté Hadoop pour le stockage et le traitement des mégadonnées.
HDFS peut stocker des fichiers de plusieurs téraoctets et prend en charge des clusters pouvant atteindre des milliers de nœuds.
Selon une étude de MarketsandMarkets, le marché mondial des systèmes de fichiers distribués devrait atteindre 24,45 milliards de dollars d'ici 2026, avec une hausse de 14,2 % entre 2020 et 2026.
Stockage objet
Le stockage objet est une approche de stockage qui gère les données en tant qu'objets, plutôt que sous forme de fichiers ou de blocs.
Chaque objet est associé à des métadonnées et un identifiant unique, permettant un accès rapide et évolutif aux données.
Amazon S3, le service de stockage objet d'AWS (Amazon Web Services), stocke plus de 100 trillions d'objets et traite en moyenne 63 millions de requêtes par seconde.
Selon une étude d'IDC, le marché mondial du stockage objet devrait atteindre 129,19 milliards de dollars d'ici 2026.
Système de stockage NoSQL
Par définition, les bases NoSQL, telles que MongoDB, Cassandra et HBase, sont conçues pour stocker et gérer des données non structurées et semi-structurées à grande échelle :
MongoDB, une base NoSQL populaire, est utilisée par plus de 18 000 clients dans plus de 100 pays, dont eBay, Adobe ou SAP.
Cassandra, une autre base de données NoSQL, peut gérer jusqu'à 600 téraoctets de données et 1 million d'opérations d'écriture par seconde sur un cluster de 400 nœuds.
Le marché mondial des bases de données NoSQL devrait atteindre 10,16 milliards de dollars d'ici 2026.
Stockage en mémoire
Le stockage en mémoire utilise la mémoire vive (RAM) pour stocker et traiter les données, offrant ainsi des performances nettement supérieures aux systèmes de stockage sur disques durs.
⚡ Stockage en mémoire (In-Memory Computing) — Technologies, performances et marché (2026)
💡 Technologie / Concept
🚀 Performance & caractéristiques
🧠 Cas d’usage typiques
📈 Données & tendances marché
Stockage en mémoire (In-Memory Storage)
Utilise la RAM pour le stockage temporaire des données, éliminant la latence liée aux disques durs.
Temps d’accès jusqu’à 10 000x plus rapide qu’un disque SSD traditionnel.
Analyses temps réel, traitement financier, e-commerce, simulation scientifique.
Marché mondial estimé à 12,12 milliards $ d’ici 2026 (MarketsandMarkets).
Apache Spark
Framework de calcul distribué en mémoire. Peut traiter les données jusqu’à 100x plus vite que Hadoop MapReduce.
Supporte le streaming, le machine learning (MLlib) et l’analyse SQL.
Traitement Big Data, analyses prédictives, pipeline de machine learning.
Utilisé par 80% des grandes entreprises data-driven (Databricks Report 2026).
SAP HANA
Base de données relationnelle en mémoire capable de traiter 1 milliard de lignes en moins d’une seconde.
Intègre le traitement OLAP et OLTP sur une seule architecture.
ERP, analyses financières, reporting temps réel, gestion de supply chain.
Adopté par 30 000+ entreprises, avec une croissance de 20% par an (IDC 2026).
Redis / Memcached
Caches en mémoire ultra-rapides pour la gestion de sessions et requêtes à haute fréquence.
Réduction de la latence réseau jusqu’à 90%.
Web apps, jeux en ligne, e-commerce, API à grande échelle.
Redis est utilisé par 60% des sites à fort trafic selon Stack Overflow Developer Survey 2026.
Databricks & Spark on Cloud
Combine le traitement en mémoire avec le cloud computing pour le scaling automatique.
Intègre MLflow pour la gestion des modèles et l’automatisation.
Analyse Big Data, IA générative, pipelines MLOps, FinTech, e-commerce.
Croissance annuelle de 17% du segment « Cloud Data Engineering » (Gartner 2026).
Google BigQuery & Snowflake
Moteurs analytiques cloud avec stockage hybride mémoire + disque.
Permettent le traitement de pétaoctets en quelques secondes via architecture serverless.
Business Intelligence, requêtes analytiques multi-sources, dashboarding.
Snowflake : +40% de croissance annuelle, BigQuery dominant sur GCP (Forrester 2026).
Le marché mondial devrait atteindre 12,12 milliards de dollars d'ici 2026.
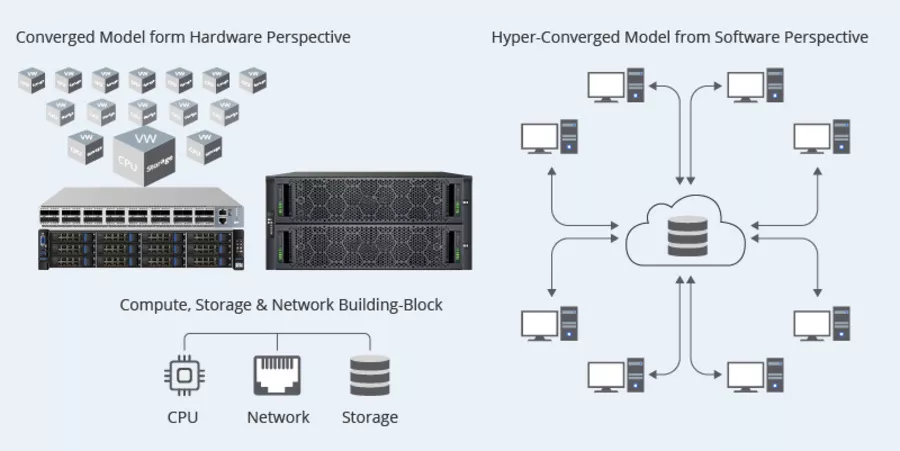
Infrastructure hyperconvergée
Les infrastructures hyperconvergées combinent le calcul, le stockage et la virtualisation dans un seul système, simplifiant ainsi la gestion et le déploiement des ressources Big Data.
Nutanix, un leader des solutions d'infrastructure hyperconvergée, compte plus de 17 000 clients dans 140 pays, dont des entreprises telles que JetBlue, Volkswagen et Hyundai.
Dell EMC VxRail, une autre solution d'infrastructure hyperconvergée populaire, a enregistré une hausse de 60 % de son chiffre d'affaires au quatrième trimestre 2020.
Le marché mondial des infrastructures hyperconvergées devrait atteindre 27,1 milliards de dollars d'ici 2026.
Ces chiffres et statistiques mettent en évidence l'importance hausse des solutions matérielles dans l'écosystème des données massives. Les sociétés investissent massivement dans ces technologies pour gérer efficacement des volumes de contenu en constante augmentation et tirer pleinement parti du potentiel des informations.
Sécurité des Données et Confidentialité
Avec le volume de données explose, la sécurité et la confidentialité deviennent des priorités absolues pour les entreprises. Le Big Data implique la gestion de données sensibles, dont la protection est essentielle pour préserver la confiance des clients et la réputation de l’entreprise.
Les organisations doivent donc investir dans des logiciels de sécurité performants, mettre en place des politiques strictes de gestion des accès et sensibiliser leurs équipes aux bonnes pratiques en matière de vie privée.
Les chiffres montrent que les entreprises qui adoptent une stratégie proactive en matière de sécurité des données réduisent significativement les risques de fuites ou de cyberattaques, tout en se conformant aux exigences réglementaires du domaine. La protection de la vie privée n’est pas seulement une obligation légale, c’est aussi un facteur clé de différenciation sur le marché.
En garantissant la confidentialité des données, les entreprises renforcent la confiance de leurs clients et s’assurent une position durable dans l’écosystème du Big Data.
Qualité des Données : Un enjeu stratégique
La qualité des données est un pilier fondamental pour toute stratégie Big Data réussie. Des données fiables, complètes et actualisées sont indispensables pour mener des analyses pertinentes et établir des prévisions précises.
Les entreprises doivent donc mettre en place des processus rigoureux de validation, utiliser des logiciels spécialisés dans le nettoyage et la gestion des données, et former leurs équipes aux meilleures pratiques de collecte et de traitement.
Selon les statistiques, les organisations qui investissent dans la qualité des données améliorent sensiblement leur capacité à prendre des décisions stratégiques et à atteindre leurs objectifs business.
Dans le domaine du Big Data, la moindre erreur ou incohérence peut fausser l’ensemble des analyses et conduire à des choix inadaptés.
Garantir la qualité des données, c’est donc maximiser la valeur des analyses, fiabiliser les prévisions et renforcer la performance globale de l’entreprise.
Formation et compétences dans le Big Data
La montée en puissance du Big Data s’accompagne d’un besoin croissant en compétences spécialisées.
Pour tirer pleinement parti des volumes de données disponibles, les entreprises doivent investir dans la formation de leurs collaborateurs aux méthodes d’analyse, aux outils de data visualisation comme Power BI, et aux langages de programmation tels que Python.
```html
🎓 Formations & Compétences incontournables en Big Data (2026)
📘 Domaine de formation
🧠 Compétences clés
🛠️ Outils / Langages
🎯 Métiers / Applications
🏅 Certifications / Programmes recommandés
Data Science & Machine Learning
– Modélisation statistique et prédictive
– Apprentissage supervisé / non supervisé
– Traitement de grandes volumétries
Python, R, TensorFlow, Scikit-learn, PyTorch
Data Scientist, ML Engineer, Analyste prédictif
Google Advanced Data Analytics (Coursera), IBM Data Science, AWS Machine Learning Specialty
Data Engineering
– Structuration et pipeline de données
– Gestion du stockage distribué
– Optimisation ETL / ELT
SQL, Spark, Hadoop, Airflow, Kafka, Snowflake
Data Engineer, Architecte Big Data, DevOps Data
Microsoft Azure Data Engineer, Google Cloud Data Engineer, Databricks Certified Data Engineer
Data Analytics & Business Intelligence
– Analyse descriptive et exploratoire
– Visualisation et storytelling des données
– KPI et reporting stratégique
Power BI, Tableau, Looker Studio, Excel avancé, SQL
Data Analyst, Business Intelligence Analyst, Consultant BI
Microsoft Power BI Data Analyst, Tableau Desktop Specialist, Google Data Analytics (Coursera)
Cloud & Infrastructure Big Data
– Stockage et calcul distribués
– Déploiement scalable (Kubernetes, Docker)
– Optimisation des coûts et sécurité cloud
AWS, Azure, Google Cloud, Terraform, Databricks
Cloud Data Architect, Big Data Administrator
AWS Certified Solutions Architect, Google Cloud Professional Data Engineer, Azure Solutions Architect Expert
Data Governance & Ethics
– Gestion de la qualité et conformité RGPD
– Sécurité et confidentialité des données
– Gouvernance et catalogage
Collibra, Alation, Informatica, Talend, BigID
Data Steward, Chief Data Officer, Analyste conformité
DAMA Certified Data Management Professional, Data Governance & Stewardship (eLearningCurve), CIPP/E (IAPP)
IA Générative & Automatisation
– Fine-tuning de modèles LLM
– Traitement automatique du langage (NLP)
– Automatisation des insights via IA
OpenAI API, LangChain, Hugging Face, Vertex AI
AI Engineer, Prompt Engineer, Data Product Manager
DeepLearning.AI Generative AI Specialization, OpenAI Fundamentals, MIT AI Strategy
```
Conclusion: Le Big Data, un défi statistique et une opportunité majeure
En fin de compte, les statistiques sur le big data illustrent son importance croissante et ses nombreux défis.
Cette nouvelle ère apporte des opportunités passionnantes, mais soulève aussi des questions sur la confidentialité et l'éthique notamment avec les réseaux sociaux.
Ceux qui ne s'adaptent pas en ne se donnant pas le moyen et en oubliant toutes les recommandations risquent d'être laissées pour compte par des concurrents plus réactifs et mieux alignés sur les attentes de leurs clients.
La transition n'est pas une option, mais une nécessité pour rester compétitif dans un environnement dynamique.
Pour chaque entreprise, l'adoption est essentielle pour innover, répondre aux besoins des clients et assurer en termes de croissance durable.
FAQ
Quel est le volume de données générées chaque jour ?
En 2024, on estime que les ensembles de données générées chaque jour dans le monde atteindront un volume de 463 exaoctets (463 milliards de gigaoctets de data).
Quelles sont les principales tendances du Big Data ?
Les principales tendances du Big Data incluent l'analyse en temps réel, l'intelligence artificielle et le développement du machine learning, le traitement des données en périphérie (edge computing), et la démocratisation de l'accès aux outils d'analyse de données.
C'est quoi les 3V ?
Ce sont les initiales de Volume (quantité de données), Vélocité (vitesse de traitement des données) et Variété (diversité des types de données).
Pourquoi les statistiques inférentielles sont-elles importantes en Big Data ?
Parce qu’elles permettent de tirer des conclusions fiables sur une population entière à partir d’un échantillon, ce qui est essentiel dans la gestion d’ensembles de données trop volumineux pour être analysés intégralement.
Quel est le rôle des statistiques descriptives ?
Elles aident à comprendre la nature, la distribution et la qualité des données, facilitant l’identification des tendances et anomalies.
Comment le Big Data impacte-t-il les décisions commerciales ?
C'est un phénomène où plus de 90% des entreprises l’utilisent pour guider leurs choix, améliorant ainsi la satisfaction client et la performance globale.
Quelles difficultés rencontrent les entreprises face au Big Data ?
Principalement l’extraction d’informations exploitables et la gestion de la qualité et de la sécurité des données, nécessitant des efforts en formation et technologies.
Quel est l’avenir du Big Data en termes de croissance ?
Le marché mondial devrait atteindre une valeur de 103 milliards de dollars d’ici 2027, avec un rythme annuel stable d’environ 11,7%.
Comment allier Big Data et respect de la vie privée ?
Par une gouvernance rigoureuse, conforme au RGPD, et un débat citoyen constant sur l’utilisation des données pour éviter le profilage intrusif.

.svg)













.avif)