Unsloth AI s’est rapidement imposé comme l’une des solutions les plus populaires pour le fine-tuning de LLM sur un ordinateur personnel ou une instance GPU abordable.
La promesse est particulièrement séduisante : accélérer l’entraînement, réduire fortement la consommation de VRAM et permettre la personnalisation de modèles de plusieurs milliards de paramètres sans disposer d’une infrastructure coûteuse.
Mais Unsloth est-il réellement aussi performant que l’affirment ses créateurs ? Cette revue analyse ses fonctionnalités, ses résultats concrets, les avis de la communauté et ses différences avec Axolotl, TRL, LLaMA-Factory et torchtune.
Avis Unsloth AI : notre verdict en bref
Unsloth est aujourd’hui l’une des meilleures solutions pour expérimenter avec des modèles open source sur un GPU grand public.
Son avantage principal ne vient pas d’un nouvel algorithme de fine-tuning révolutionnaire. Il repose surtout sur une implémentation très optimisée de méthodes connues comme LoRA et QLoRA, combinée à des kernels personnalisés et à une gestion agressive de la mémoire.
Avis Unsloth AI en 2026 : notre verdict sur le fine-tuning open source
Critère évalué 🧭
Notre note ⭐
Commentaire concret 📝
Verdict rapide 🔎
Vitesse d’entraînement
⚡ 9,2/10
Excellente sur un GPU unique grâce aux kernels optimisés
✅ Idéal pour multiplier rapidement les expérimentations
Optimisation mémoire
💾 9,5/10
Réduction importante de la VRAM avec LoRA et QLoRA
✅ Son principal avantage sur un GPU grand public
Compatibilité des modèles
9,0/10
Écosystème étendu et régulièrement actualisé
✅ Convient à de nombreux modèles open source
Facilité d’utilisation
8,4/10
Notebooks accessibles et interface Unsloth Studio
✅ Démarrage rapide malgré un fine-tuning encore technique
Stabilité technique
7,8/10
Certaines mises à jour peuvent introduire des incompatibilités
⚠️ Figer les dépendances avant un projet important
Scalabilité multi-GPU
7,5/10
Possible, mais moins fluide que certains frameworks distribués
⚠️ Axolotl reste plus naturel pour les grands clusters
Rapport performance-prix
💰 9,4/10
Excellent pour prototyper sans infrastructure coûteuse
✅ Très pertinent pour les indépendants et petites équipes
Unsloth constitue un choix particulièrement pertinent pour les développeurs, chercheurs indépendants, petites équipes et passionnés souhaitant réaliser un fine-tuning économique.
Il est moins évident pour les grandes infrastructures distribuées, les environnements extrêmement réglementés ou les équipes qui recherchent une chaîne d’entraînement parfaitement stable sur plusieurs GPU.
Qu’est-ce qu’Unsloth AI ?
Unsloth est une librairie open source conçue pour accélérer l’entraînement, le post-entraînement et l’exécution de modèles d’intelligence artificielle.
Le projet se décline désormais en deux expériences complémentaires.
Unsloth Core
Unsloth Core correspond à la bibliothèque Python historique.
Elle permet aux développeurs d’utiliser directement Unsloth dans leurs scripts, leurs notebooks Jupyter ou leurs environnements Hugging Face.
Cette version reste la plus flexible pour les utilisateurs techniques souhaitant contrôler précisément :
les paramètres LoRA ou QLoRA ;
la préparation des données ;
le gradient checkpointing ;
la longueur de contexte ;
les étapes d’entraînement et d’évaluation.
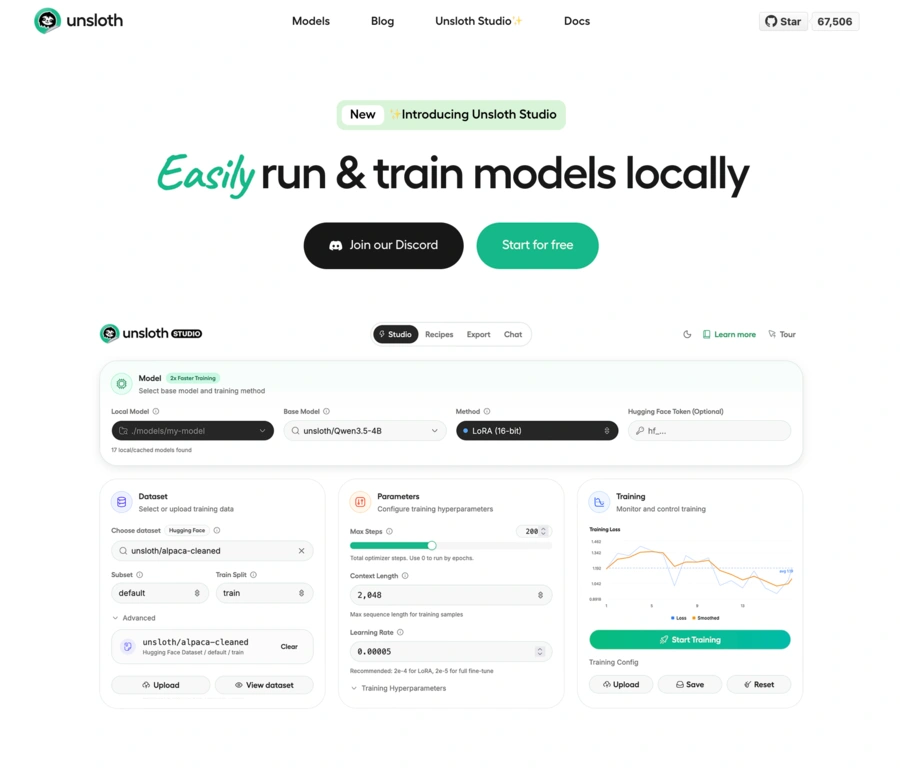
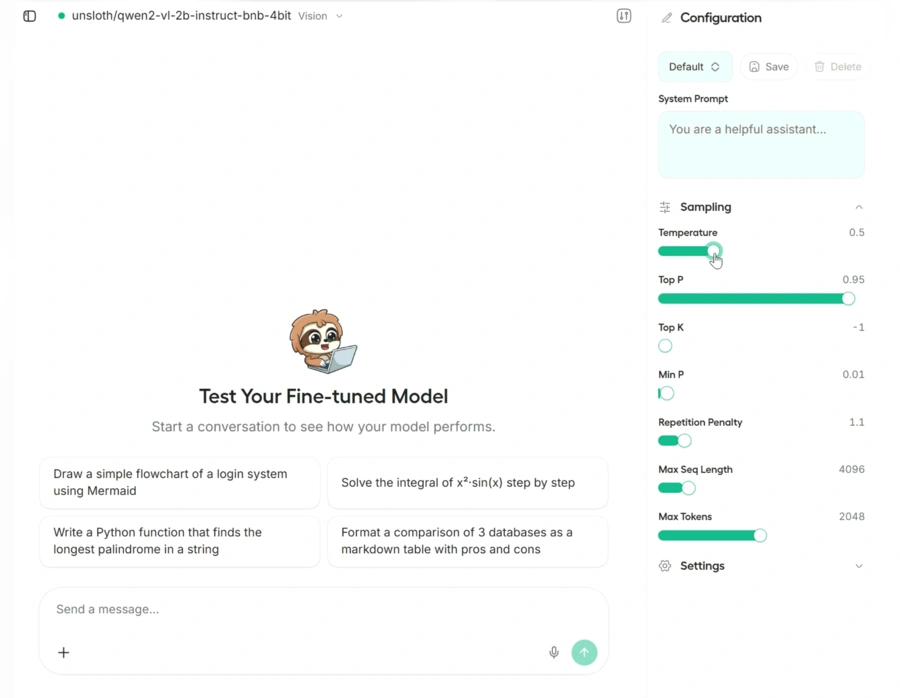
Unsloth Studio
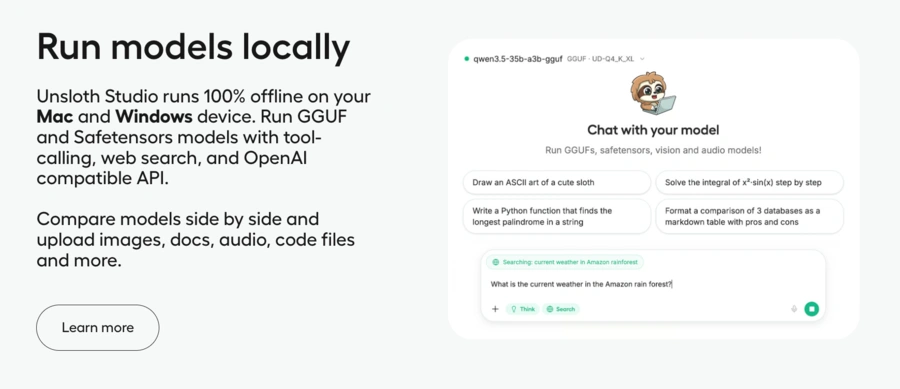
Unsloth Studio est une interface Web open source fonctionnant localement.
Cette interface vise à réunir dans un même environnement la préparation des données, l’entraînement, l’observation des métriques, l’inférence et l’exportation des modèles.
Elle prend notamment en charge les modèles de texte, de vision, d’audio, de synthèse vocale et d’embeddings.
Cette évolution rapproche Unsloth d’outils comme LLaMA-Factory ou LM Studio, tout en conservant son moteur d’optimisation spécialisé dans l’entraînement.
Comment Unsloth accélère-t-il le fine-tuning des LLM ?
Unsloth ne se contente pas d’ajouter une interface autour de Hugging Face.
La bibliothèque réécrit ou optimise plusieurs opérations utilisées pendant l’entraînement des modèles de langage.
Elle s’appuie notamment sur :
des kernels CUDA personnalisés ;
des kernels Triton optimisés ;
une allocation mémoire plus efficace ;
le gradient checkpointing ;
des implémentations spécialisées de LoRA et QLoRA.
Ces optimisations réduisent les transferts de données inutiles entre la mémoire du GPU et les unités de calcul.
Le résultat peut être une diminution importante de la VRAM nécessaire ainsi qu’une meilleure utilisation de la puissance disponible.
Une accélération réellement perceptible
La documentation d’Unsloth avance généralement une accélération proche de deux fois par rapport à certaines configurations classiques utilisant Hugging Face et FlashAttention.
Des publications de Hugging Face et plusieurs tutoriels indépendants ont également observé des gains significatifs sur des scénarios de fine-tuning en QLoRA.
Ces chiffres doivent toutefois être interprétés avec prudence.
Le gain dépend fortement :
du modèle sélectionné ;
de la longueur des séquences ;
du type de GPU ;
de la taille des lots ;
des versions de PyTorch, CUDA, Triton et Transformers.
Un entraînement deux fois plus rapide sur un modèle et un GPU précis ne signifie donc pas que tous les projets bénéficieront systématiquement du même facteur d’accélération.
Unsloth réduit-il réellement la consommation de VRAM ?
La réduction de VRAM est probablement l’argument le plus convaincant d’Unsloth.
Grâce à QLoRA, les poids du modèle de base sont chargés en précision 4 bits. Seuls de petits adaptateurs LoRA sont ensuite entraînés.
Unsloth optimise davantage cette approche afin de limiter la mémoire utilisée par les activations, les gradients et certaines opérations intermédiaires.
Estimation de la VRAM nécessaire
Les valeurs suivantes sont des minimums indicatifs. La longueur du contexte, la taille des lots et les paramètres LoRA peuvent augmenter les besoins réels.
Mémoire GPU estimée en 2026 selon la taille du modèle et la méthode d’entraînement
Taille du modèle 🧠
QLoRA 4 bits 📉
LoRA 16 bits 📈
Configuration possible 🖥️
🟢 3B
Environ 3,5 Go
Environ 8 Go
Petit GPU compatible ou environnement Colab
🟢 7B
💾 ≈ 5 Go
Environ 19 Go
RTX 3060 ou carte graphique supérieure
🟡 8B
Environ 6 Go
Environ 22 Go
RTX 3060, RTX 3090 ou RTX 4090
🟡 14B
Environ 8,5 Go
Environ 33 Go
QLoRA envisageable sur un GPU grand public récent
🟠 27B
Environ 22 Go
Environ 64 Go
RTX 3090 ou RTX 4090 recommandée en QLoRA
🟠 32B
Environ 26 Go
Environ 76 Go
GPU doté de 32 à 48 Go de mémoire recommandé
🔴 70B
💾 ≈ 41 Go
Environ 164 Go
GPU professionnel ou configuration équipée de plusieurs GPU
Ces estimations démontrent pourquoi Unsloth est apprécié par les utilisateurs possédant une RTX 3090 ou une RTX 4090.
Avec 24 Go de VRAM, ces cartes peuvent entraîner en QLoRA des modèles qui nécessiteraient normalement une infrastructure bien plus coûteuse.
Unsloth face à Axolotl, LLaMA-Factory, TRL et torchtune
Le meilleur outil dépend moins de la vitesse pure que du type de projet.
Unsloth face à Axolotl, LLaMA-Factory, TRL et torchtune en 2026
Solution 🧩
Principal avantage ✨
Limite ⚠️
Profil idéal 👥
🦥 Unsloth
– Entraînement rapide et mémoire GPU optimisée
– Fine-tuning accessible sur 💾 1 GPU
Écosystème très mouvant, avec des changements fréquents
Utilisateur disposant d’une mémoire GPU limitée
🦎 Axolotl
– Configuration avancée et nombreux paramètres
– Entraînement distribué 🖥️ Multi-GPU
Fichiers YAML plus techniques à configurer et maintenir
Équipe ML utilisant une infrastructure distribuée
🏭 LLaMA-Factory
Interface visuelle et compatibilité avec de nombreux modèles
Certaines couches d’abstraction rendent le pipeline moins transparent
Débutant, formateur ou utilisateur privilégiant une interface graphique
🤗 TRL
Intégration directe avec Hugging Face Transformers
Optimisation mémoire et performances à configurer soi-même
Chercheur travaillant déjà dans l’écosystème Hugging Face
🔥 torchtune
Code PyTorch lisible, modulaire et facilement personnalisable
Prise en main plus technique pour les utilisateurs débutants
Recherche et création de pipelines d’entraînement sur mesure
Pour quels cas d’usage Unsloth est-il recommandé ?
Unsloth est particulièrement adapté aux situations suivantes.
Pour quels cas d’usage Unsloth est-il recommandé en 2026 ?
Cas d’usage 🧩
Pertinence ⭐
Pourquoi 🎯
🧪 Prototype de modèle spécialisé
✅ Excellente
– Itérations rapides sur des jeux de données ciblés
– Coût GPU réduit pendant les expérimentations
💻 Fine-tuning sur RTX 3090 ou 4090
Excellente
Très bonne optimisation de la VRAM sur un GPU unique
📚 Assistant métier
Très bonne
Adapte le style, le vocabulaire et les formats attendus
🧾 Extraction structurée
Très bonne
Apprend à restituer des champs selon des exemples spécialisés
🤖 Modèle local privé
🔒 Excellente
Conserve les données et l’entraînement sur l’infrastructure locale
🎓 Apprentissage du fine-tuning
Bonne
Nombreux notebooks, exemples et tutoriels pour démarrer rapidement
🏢 Entraînement distribué massif
Moyenne
D’autres frameworks sont plus matures pour les grands clusters
🔒 Environnement fortement réglementé
Variable
– Figer les versions et dépendances utilisées
– Auditer le pipeline avant toute mise en production
Unsloth est également pertinent pour tester plusieurs modèles avant de choisir une architecture définitive.
Sa model training efficiency permet de consacrer davantage de ressources aux expérimentations plutôt qu’à un seul entraînement coûteux.
Les situations où Unsloth est moins adapté
Unsloth n’est pas systématiquement le meilleur choix.
Il peut être préférable de choisir une autre solution lorsque :
le pipeline doit fonctionner sur plusieurs dizaines de GPU ;
l’équipe exige un support commercial avec des engagements contractuels précis ;
chaque dépendance doit rester figée pendant plusieurs années ;
le modèle utilisé n’est pas encore correctement pris en charge ;
l’objectif nécessite de modifier profondément les composants PyTorch internes.
Dans ces situations, une solution plus modulaire ou une plateforme gérée peut être plus adaptée.
Avantages et inconvénients
Quels sont les avantages et inconvénients d’Unsloth en 2026 ?
Critère 🧭
Avantages ✅
Inconvénients ⚠️
Mémoire GPU
Réduction importante de la VRAM nécessaire 💾 Optimisée
Installation parfois sensible aux versions de CUDA et PyTorch
Performances
Accélération réelle sur de nombreux scénarios de fine-tuning
Gains variables selon le modèle, le matériel et la configuration
Écosystème Hugging Face
Très bonne compatibilité avec Transformers, TRL et les modèles populaires
Les évolutions rapides peuvent rendre certains exemples incompatibles
Export des modèles
– Export vers Ollama et llama.cpp
– Formats adaptés à l’inférence locale
L’export GGUF peut demander des ajustements ou échouer selon le modèle
Prise en main
Nombreux notebooks prêts à utiliser pour démarrer rapidement
Le fine-tuning reste technique pour un utilisateur débutant
Ouverture et confidentialité
Fonctionnement local et code open source 🔒 Local
La sécurité dépend toujours de l’environnement et des dépendances installées
Évolutivité
Support rapide de nombreux modèles récemment publiés
– Expérience multi-GPU encore moins fluide
– Certaines fonctions de Studio restent en bêta
API et accompagnement
API locale compatible avec le format OpenAI
Offres et modalités de support professionnel peu détaillées publiquement
Tarifs
La version open source d’Unsloth peut être utilisée gratuitement.
L’utilisateur doit néanmoins prendre en compte le coût du matériel ou de la location d’un GPU.
Pour un petit modèle, un notebook gratuit ou une instance louée pendant quelques heures peut suffire.
Des offres professionnelles existent pour les entreprises ayant besoin de performances supplémentaires, d’un accompagnement ou de fonctions avancées. Leurs tarifs et conditions ne sont pas clairement affichés publiquement et doivent être demandés à l’équipe d’Unsloth.
Combien coûte Unsloth en 2026 ? Logiciel, GPU et offre professionnelle
Élément 🧩
Coût potentiel 💰
À prévoir 🔎
🆓 Bibliothèque open source
💳 0 €
Le logiciel est gratuit, mais le calcul reste à financer
📓 Google Colab gratuit
💳 0 €
Sessions, disponibilité GPU et durée d’exécution limitées
☁️ Location ponctuelle de GPU
Variable selon le fournisseur et le GPU
Paiement à l’heure, adapté aux entraînements occasionnels
💻 GPU local
Investissement matériel initial
– Coût d’achat, d’électricité et de maintenance
– Rentable pour un usage régulier
🏢 Offre professionnelle Unsloth
Tarification sur demande
Accompagnement, fonctionnalités avancées et besoins d’entreprise
Le support client d’Unsloth est-il satisfaisant ?
Pour la version open source, le support repose principalement sur la documentation, GitHub, Discord et la communauté.
L’équipe est active et publie fréquemment des correctifs, mais le nombre important de modèles et d’environnements peut entraîner des délais ou des réponses variables.
Le support clients Unsloth destiné aux entreprises semble passer par une prise de contact commerciale.
Avant de déployer Unsloth dans un environnement critique, il est conseillé de vérifier précisément :
les délais de réponse ;
les engagements de service ;
les versions prises en charge ;
l’accompagnement pour le multi-GPU ;
les conditions de maintenance.
Bonnes pratiques pour réussir son fine-tuning avec Unsloth
Commencez par un modèle relativement petit et un jeu de données représentatif.
Établissez ensuite une performance de référence avant l’entraînement.
Bonnes pratiques pour réussir son fine-tuning avec Unsloth en 2025
Étape 🧭
Action recommandée 🛠️
Objectif 🎯
Validation attendue ✅
1️⃣ Baseline
Tester le modèle d’origine sur des exemples représentatifs
Mesurer précisément le point de départ
Conserver les résultats de référence 📊 Avant
2️⃣ Données
– Nettoyer les exemples incorrects ou dupliqués
– Uniformiser les formats d’entrée et de sortie
Réduire le bruit et les réponses incohérentes
Échantillon relu, cohérent et adapté au cas d’usage
3️⃣ Petit test
Entraîner d’abord sur un échantillon limité
Valider le pipeline sans mobiliser trop de ressources
Entraînement terminé sans erreur ni consommation anormale
4️⃣ Évaluation
Comparer le modèle avant et après le fine-tuning
Vérifier que l’entraînement apporte un gain réel
– Amélioration sur les tâches ciblées
– Absence de régression majeure
5️⃣ Export
Tester les formats GGUF ou Safetensors
Valider l’inférence dans l’environnement final
Modèle chargé et interrogé correctement 📦 Déployable
6️⃣ Reproduction
– Figer les versions et dépendances
– Archiver paramètres, données et commandes
Pouvoir relancer la même expérience
Résultats reproductibles sur un environnement propre
Pour un premier projet, QLoRA avec un faible nombre d’époques représente généralement le meilleur compromis.
Il est ensuite possible d’ajuster le taux d’apprentissage, le rang LoRA et les modules ciblés à partir des résultats observés.
Conclusion : notre avis final sur Unsloth AI
Notre avis sur Unsloth AI est largement positif.
La plateforme rend le fine-tuning LLM plus accessible en réduisant le temps d’entraînement, la consommation de mémoire et le coût des expérimentations.
Elle se démarque particulièrement sur un GPU unique comme une RTX 3090 ou une RTX 4090. Sa compatibilité avec Hugging Face, ses notebooks, son export GGUF et la nouvelle interface Unsloth Studio en font un écosystème de plus en plus complet.
Ses limites ne doivent cependant pas être ignorées. Les dépendances évoluent rapidement, certains exports peuvent échouer et l’expérience multi-GPU reste moins fluide que celle de frameworks spécialisés.
Unsloth ne remplace pas la qualité des données, une méthodologie d’évaluation sérieuse ou une bonne compréhension du fine-tuning.
Pour un développeur, un data scientist ou une petite équipe souhaitant personnaliser rapidement un modèle open source sans investir dans une infrastructure massive, Unsloth figure néanmoins parmi les solutions les plus performantes et les plus intéressantes du marché.
LoRA et QLoRA : quelle méthode choisir avec Unsloth ?
LoRA et QLoRA entraînent uniquement de petits adaptateurs ajoutés au modèle d’origine.
La principale différence réside dans la précision utilisée pour charger le modèle de base.
LoRA, QLoRA ou fine-tuning complet en 2026 : précision, avantages et limites
Méthode 🧩
Précision 🔢
Avantage principal ✨
Limite principale ⚠️
⚡ LoRA
🔢 16 bits
– Bonne précision numérique
– Entraînement rapide des adaptateurs
Consommation de VRAM supérieure à QLoRA
💾 QLoRA
📉 4 bits
Réduction importante de la mémoire GPU nécessaire
Légère perte potentielle de précision liée à la quantification
🏗️ Fine-tuning complet
16 ou 32 bits
Modification de l’ensemble des paramètres du modèle
– Besoins matériels très élevés
– Coût d’entraînement et de stockage supérieur
Pour la majorité des prototypes, Unsloth recommande de commencer avec QLoRA.
Cette approche permet d’entraîner des modèles de plusieurs milliards de paramètres sur un GPU consumer-grade tout en conservant une qualité généralement proche de LoRA.
Le fine-tuning complet reste utile pour certains projets de recherche ou pour des transformations importantes du modèle, mais il est rarement nécessaire pour adapter un assistant à un domaine, un format ou un style précis.
Fonctionnalités principales d’Unsloth
L’écosystème Unsloth dépasse désormais le simple entraînement de modèles Llama.
Fonctionnalités principales d’Unsloth en 2026 : entraînement, export et modèles multimodaux
Fonctionnalité 🧩
Utilité concrète 🎯
Niveau d’intérêt ⭐
🦥 Fine-tuning LoRA et QLoRA
Personnaliser un modèle avec moins de mémoire GPU
🔥 Très élevé
⚙️ Kernels CUDA et Triton
Accélérer les calculs tout en réduisant la consommation de VRAM
Très élevé
🤗 Compatibilité Hugging Face
Utiliser Transformers, PEFT, TRL et le Hub
🔗 Très élevé
📓 Notebooks prêts à l’emploi
Entraîner un modèle sur Colab, Kaggle ou localement
Élevé
🖥️ Unsloth Studio
Préparer, entraîner et exporter un modèle sans coder
Élevé
📦 Exportation GGUF
Déployer le modèle dans Ollama, llama.cpp ou une application locale
📦 Très élevé
🔌 API compatible OpenAI
Connecter des applications et agents à un modèle local
Élevé
🎯 SFT, DPO, GRPO et RL
Appliquer différentes méthodes de post-entraînement selon l’objectif
Élevé
👁️ Vision, audio et embeddings
Personnaliser des modèles multimodaux et des représentations vectorielles
🚧 En évolution
📊 Suivi d’entraînement
Observer la perte, les métriques et la progression des étapes
Utile pour diagnostiquer et comparer les entraînements
L’outil fonctionne avec des composants largement utilisés comme :
Transformers ;
PEFT ;
TRL ;
Datasets ;
le Hugging Face Hub.
Cette compatibilité permet de conserver une grande partie des habitudes et du code déjà utilisés dans l’écosystème Hugging Face.
Un développeur peut par exemple charger un modèle, lui ajouter des adaptateurs LoRA, utiliser un SFTTrainer, puis publier le résultat sur le Hub.
Unsloth ne cherche donc pas à remplacer tout l’écosystème. Il agit plutôt comme une couche d’optimisation spécialisée.
Quels modèles sont compatibles avec Unsloth ?
Unsloth prend en charge plusieurs centaines de modèles et variantes.
Parmi les familles régulièrement proposées figurent notamment :
Llama
Qwen ;
Gemma ;
Mistral ;
DeepSeek ;
GLM.
La plateforme s’étend également aux modèles multimodaux, aux modèles de vision, aux embeddings et à la synthèse vocale.
Un catalogue de modèles préquantifiés est disponible afin d’éviter aux utilisateurs d’effectuer eux-mêmes certaines conversions.
Cette disponibilité facilite le prototypage rapide, mais elle crée aussi une dépendance aux modèles, aux gabarits de conversation et aux formats maintenus par Unsloth.
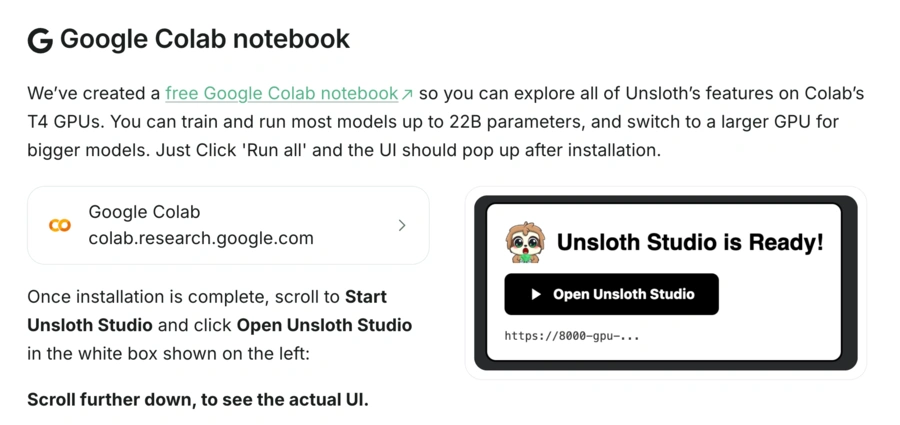
Peut-on utiliser Unsloth sur Google Colab ?
Unsloth est particulièrement populaire pour l’entraînement sur Google Colab.
Les notebooks officiels permettent généralement de :
charger un modèle compatible ;
importer un jeu de données ;
configurer les adaptateurs LoRA ;
lancer l’entraînement ;
exporter le modèle ou l’adaptateur.
Pour un premier test, cette approche est beaucoup plus simple que l’installation complète d’un environnement CUDA local.
Elle convient bien aux étudiants, aux développeurs indépendants et aux utilisateurs qui souhaitent évaluer un cas d’usage avant d’acheter un GPU.
Les sessions gratuites restent néanmoins limitées. Leur disponibilité, leur durée et le type de GPU attribué peuvent varier.
Exemple avec une RTX 3090
Imaginons un développeur souhaitant adapter un modèle de 8 milliards de paramètres aux questions techniques de son entreprise.
Il dispose d’une RTX 3090 avec 24 Go de VRAM.
Avec une configuration traditionnelle en pleine précision, cette carte serait rapidement insuffisante. Avec Unsloth et QLoRA, le modèle peut être chargé en 4 bits et entraîné à l’aide de petits adaptateurs.
Le développeur peut alors :
tester plusieurs jeux de données ;
comparer différents rangs LoRA ;
réduire le temps d’entraînement ;
exporter le résultat en GGUF ;
exécuter le modèle localement avec Ollama ou llama.cpp.
Le véritable bénéfice n’est pas uniquement de terminer un entraînement plus rapidement. Il est surtout de pouvoir multiplier les expérimentations avec un matériel déjà disponible.
Exportation des modèles en GGUF
Unsloth permet d’exporter un modèle entraîné vers le format GGUF.
Ce format est particulièrement utilisé par llama.cpp et de nombreuses applications d’inférence locale.
Un modèle exporté peut ensuite être exécuté dans des outils comme :
Ollama ;
llama.cpp ;
LM Studio ;
Open WebUI ;
Unsloth Studio.
Plusieurs niveaux de quantification sont disponibles, notamment Q4, Q8 et F16.
Cette étape est pratique, mais elle fait aussi partie des points sur lesquels les utilisateurs rencontrent le plus de problèmes.
Certaines versions de modèles, certains gabarits de conversation ou certaines évolutions de llama.cpp peuvent provoquer une conversion incomplète ou un comportement incorrect après l’exportation.
Il est donc indispensable de tester le fichier final avant de supprimer les checkpoints d’origine.
L’API Unsloth est-elle utile ?
L’API Unsloth correspond principalement à un point d’accès local compatible avec les interfaces utilisées par OpenAI.
Elle permet d’exposer un modèle local à des applications externes sans devoir réécrire toute leur couche d’intégration.
Cette API peut notamment servir à connecter :
un script Python ;
une interface de discussion ;
un agent de programmation ;
Claude Code ou Codex via une configuration compatible ;
une application utilisant déjà un client OpenAI.
Cette fonctionnalité ne doit pas être confondue avec un service d’inférence propriétaire entièrement hébergé dans le cloud.
L’intérêt principal réside dans la possibilité de conserver le modèle et les données sur sa propre machine ou de faire tourner Unsloth avec des outils comme Hermes Agent.
Que pensent les utilisateurs d’Unsloth ?
Les avis communautaires sont globalement favorables, particulièrement parmi les utilisateurs disposant d’un seul GPU.
Les retours positifs mentionnent régulièrement la rapidité de mise en route, les économies de VRAM et la disponibilité de notebooks pour les modèles récents.
Les points les plus appréciés
Unsloth en 2026 : les points les plus appréciés par les utilisateurs
Retour fréquent 💬
Pourquoi cela compte 🎯
Bénéfice concret ✨
⚡ Entraînement plus rapide
Permet de tester davantage de configurations dans le même temps
Itérations accélérées et comparaison plus rapide des résultats ⏱️ Rapide
💾 Faible consommation mémoire
Rend le fine-tuning accessible sur des GPU grand public
Modèles plus grands utilisables avec une VRAM limitée 📉 VRAM
📓 Notebooks fonctionnels
Réduit le temps consacré à l’installation et à la configuration
Démarrage facilité sur Colab, Kaggle ou une machine locale
🤗 Écosystème Hugging Face
Évite de reconstruire entièrement le pipeline d’entraînement
Réutilisation de Transformers, PEFT, TRL et du Hub
🆓 Projet open source
Permet d’inspecter, modifier et adapter le code aux besoins
Meilleure transparence et personnalisation du pipeline
Les développeurs apprécient également la rapidité avec laquelle les nouveaux modèles sont ajoutés.
Lorsqu’une nouvelle famille comme Gemma ou Qwen apparaît, des notebooks et des versions quantifiées sont souvent publiés rapidement.
Les critiques et problèmes relevés
Les retours négatifs portent moins sur les performances fondamentales que sur la stabilité de l’environnement.
Unsloth en 2026 : problèmes fréquents, conséquences et précautions
Problème signalé ⚠️
Conséquence possible 💥
Précaution recommandée 🛡️
🧱 Conflits CUDA, PyTorch ou Triton
Installation ou compilation impossible ⛔ Blocage
– Vérifier la matrice de compatibilité
– Figer les versions fonctionnelles
📦 Export GGUF défaillant
Modèle inutilisable après l’entraînement
– Tester l’export sur un petit modèle
– Valider le fichier dans llama.cpp ou Ollama
🔄 Mises à jour très fréquentes
Régression d’un notebook auparavant fonctionnel
Conserver un environnement reproductible avec ses dépendances
🖥️ Support matériel inégal
Expérience variable entre NVIDIA, AMD, Intel et macOS
Vérifier le support réel du modèle et de l’accélérateur
🧩 Multi-GPU plus complexe
Configuration moins fluide pour les infrastructures distribuées
Privilégier un framework distribué plus mature si nécessaire 🖥️ Cluster
Le projet évolue très rapidement. Cette vitesse constitue une force pour le support des nouveaux modèles, mais elle peut aussi créer des incompatibilités temporaires.
Unsloth améliore-t-il les performances du modèle ?
Unsloth améliore principalement la performance computationnelle de l’entraînement.
Il ne garantit pas automatiquement une amélioration de la qualité des réponses.
La qualité finale dépend principalement :
du modèle de base ;
de la qualité du jeu de données ;
du format des exemples ;
des hyperparamètres ;
de la méthode d’évaluation.
Un mauvais jeu de données entraîné deux fois plus rapidement reste un mauvais jeu de données.
Il est donc préférable de comparer le modèle avant et après le fine-tuning sur un ensemble de tests séparé.
Les affirmations d’absence de perte de précision doivent également être replacées dans leur contexte. Elles correspondent à des configurations et benchmarks précis, et non à une garantie valable pour chaque projet.
Unsloth est-il fiable ?
Unsloth est suffisamment fiable pour le prototypage, la recherche, les projets personnels et de nombreux cas professionnels.
Son adoption sur GitHub, son intégration dans l’écosystème Hugging Face et la quantité de notebooks disponibles témoignent d’un projet actif.
La fiabilité d’un pipeline précis dépend néanmoins de la maîtrise de ses versions.
Pour un projet important, il est conseillé de verrouiller :
la version d’Unsloth ;
la version de PyTorch ;
la version de Transformers ;
la version de TRL ;
la version de CUDA ou ROCm.
Une mise à jour automatique de toutes les dépendances juste avant un entraînement important peut provoquer des erreurs difficiles à diagnostiquer.
Unsloth fonctionne-t-il sous Windows, Linux et macOS ?
Unsloth Studio peut être installé sous Windows, Linux, WSL et macOS.
Le niveau de prise en charge de l’entraînement diffère cependant selon le matériel.
Compatibilité d’Unsloth en 2026 : inférence, entraînement et maturité
Environnement 🖥️
Inférence ⚡
Entraînement 🧠
Maturité 📊
🟢 Linux + NVIDIA
Oui
Oui
✅ Excellente
🟢 Windows + NVIDIA
Oui
Oui
Bonne, avec une installation parfois plus sensible
🟢 WSL + NVIDIA
Oui
Oui
Bonne pour conserver un environnement proche de Linux
🟡 GPU Intel
Selon le matériel et la configuration
Disponible via Unsloth Core
Plus technique à installer et à optimiser
🟡 GPU AMD
Oui pour plusieurs modèles et usages
Disponible via Unsloth Core
Support en progression selon les configurations
🟠 macOS Apple Silicon
Oui
Support MLX encore évolutif
🔎 À vérifier selon la version
🟡 CPU uniquement
Oui, mais lentement
Peu adapté au fine-tuning
Réservé aux petits modèles et aux tests simples
Pour obtenir l’expérience la plus stable, Linux avec un GPU NVIDIA reste généralement la configuration la plus simple.
FAQ
Unsloth est-il open source ?
Oui, le dépôt principal est publié sous une licence open source. Certaines offres ou optimisations professionnelles peuvent néanmoins être proposées séparément.
Peut-on utiliser Unsloth avec une RTX 3090 ?
Oui. La RTX 3090 et ses 24 Go de VRAM constituent une excellente configuration pour le fine-tuning local en QLoRA de modèles de 7B, 8B, 14B et, selon les paramètres, de modèles plus importants.
Peut-on entraîner un LLM sans GPU NVIDIA ?
Unsloth prend désormais en charge davantage de configurations Intel et AMD via Unsloth Core. L’expérience la plus mature reste toutefois celle proposée sur les GPU NVIDIA.
Unsloth fonctionne-t-il avec Ollama ?
Oui. Le modèle entraîné peut être exporté en GGUF puis importé dans Ollama. Il est également possible de connecter Ollama à certaines fonctions d’Unsloth Studio.
Unsloth peut-il améliorer les connaissances d’un modèle ?
Un fine-tuning peut apprendre des comportements, des formats et certaines informations spécialisées. Pour des connaissances fréquemment mises à jour, une architecture RAG est souvent plus adaptée.
Unsloth est-il adapté aux débutants ?
Les notebooks et Unsloth Studio rendent l’outil accessible à un débutant motivé. Une compréhension minimale des jeux de données, de LoRA et des métriques reste néanmoins nécessaire.
Unsloth est-il meilleur que LLaMA-Factory ?
Unsloth est généralement plus orienté vers l’optimisation des performances et de la mémoire. LLaMA-Factory offre une interface mature et une configuration très large. LLaMA-Factory peut aussi utiliser Unsloth comme moteur.
Peut-on utiliser Unsloth en production ?
Oui, à condition de figer les dépendances, tester les exports, documenter le pipeline et mesurer précisément la qualité du modèle. Pour un système critique, un accompagnement professionnel peut être nécessaire.
Unsloth prend-il en charge plusieurs GPU ?
Unsloth Core peut être utilisé avec des outils comme Accelerate, Distributed Data Parallel, FSDP ou DeepSpeed.
Le support multi-GPU existe donc, mais il n’est pas encore aussi transparent que l’expérience proposée sur un seul GPU.
Unsloth Studio automatise déjà certaines configurations d’inférence multi-GPU, tandis que son expérience d’entraînement distribué continue d’évoluer.
Pour un serveur comprenant plusieurs cartes A100 ou H100, Axolotl ou torchtune peuvent offrir une architecture distribuée plus explicite et plus prévisible.
Les benchmarks d’Unsloth sont-ils crédibles ?
Les benchmarks officiels montrent des gains impressionnants en vitesse, en mémoire et en longueur de contexte.
Une partie de ces gains est cohérente avec les observations publiées dans l’écosystème Hugging Face.
Il faut néanmoins éviter de considérer les benchmarks d’un éditeur comme une vérité universelle.
En 2026, un préprint consacré à un framework concurrent a contesté la validité d’un benchmark précis d’Unsloth, affirmant que la configuration mesurée ne réalisait pas correctement l’entraînement.
Cette critique ne démontre pas que toutes les performances d’Unsloth sont incorrectes. Elle rappelle surtout l’importance de reproduire les tests avec son propre modèle, ses données et son matériel.
La meilleure mesure reste le temps nécessaire pour atteindre une qualité donnée sur votre propre cas d’usage.
Unsloth est-il facile à utiliser pour les débutants ?
Unsloth est plus accessible que beaucoup de bibliothèques de fine-tuning, mais il ne transforme pas l’entraînement d’un LLM en opération totalement automatique.
Les notebooks réduisent fortement la difficulté technique. Unsloth Studio simplifie encore davantage la configuration grâce à son interface visuelle.
Un utilisateur non expert peut lancer un premier entraînement en suivant un tutoriel.
Il devra cependant comprendre plusieurs notions pour obtenir un bon résultat :
différence entre un modèle de base et un modèle instruct ;
structure du jeu de données ;
gabarit de conversation ;
taux d’apprentissage ;
nombre d’époques et risque de surapprentissage.
L’interface utilisateur intuitive simplifie les commandes, mais elle ne remplace pas les connaissances nécessaires pour concevoir une expérience correcte.
TRANSPARENCE SUR LES PARTENARIATS Nous sélectionnons nos partenaires en fonction de leur qualité et fiabilité. Notre équipe les teste et les approuve indépendamment des accords commerciaux. Si vous achetez ou souscrivez via nos liens partenaires, nous pouvons recevoir une commission. Cela ne vous coûte rien de plus et aide à maintenir ce contenu gratuit. Pour en savoir plus, consultez notre engagement qualité.
.svg)