Avis Ollama : ce logiciel est devenu l’une des solutions les plus populaires pour télécharger, exécuter et intégrer des modèles d’intelligence artificielle sur son propre ordinateur. Il permet notamment d’utiliser des LLM localement, sans envoyer systématiquement ses documents ou ses conversations vers un fournisseur externe.
En 2026, Ollama ne se limite toutefois plus à l’exécution locale de l’IA. La plateforme propose également des modèles cloud, une application de bureau, des intégrations avec des outils de développement et des interfaces compatibles avec une partie des API d’OpenAI et d’Anthropic.
Notre avis sur Ollama en bref
Ollama est particulièrement convaincant pour les développeurs, les makers et les professionnels qui souhaitent construire des applications utilisant des modèles open source ou open weights, tout en conservant une grande maîtrise de leur infrastructure.
Son principal défaut reste sa dépendance au matériel. L’installation du logiciel est simple, mais obtenir de bonnes performances, choisir la bonne quantification et configurer une grande fenêtre de contexte demandent davantage de connaissances.
Avis Ollama en 2026 : notre évaluation de l’IA locale
Critère 🧭
Notre évaluation ⭐
Avis synthétique 📝
Lecture rapide 🔎
Installation
🚀 9/10
Installation rapide sur Windows, macOS et Linux
✅ Premiers modèles exécutés en quelques commandes
Confidentialité locale
🔐 9/10
Les requêtes locales restent sur la machine utilisée
✅ Pertinent pour les données sensibles et privées
Performances
7,5/10
Excellentes avec un GPU adapté, plus variables sans accélération
⚠️ La taille du modèle doit correspondre au matériel
Intégrations
🔌 9/10
API, Docker, outils de code et nombreuses interfaces compatibles
✅ Facile à connecter aux applications et agents locaux
Facilité pour débuter
7,5/10
Accessible, mais l’écosystème reste orienté développeurs
💡 Une interface graphique facilite les premiers essais
Usage en entreprise
7/10
Puissant, mais nécessite gouvernance, sécurité et supervision
⚠️ Encadrer modèles, accès, journaux et mises à jour
Rapport qualité-prix
💰 9/10
Logiciel local gratuit, avec services cloud facultatifs
✅ Excellent pour prototyper sans abonnement obligatoire
Verdict : Ollama est l’un des meilleurs points d’entrée pour utiliser un LLM en local ou intégrer facilement des modèles ouverts dans une application. Il n’est cependant pas automatiquement le meilleur moteur pour une infrastructure à très forte concurrence, ni l’interface la plus intuitive pour un utilisateur totalement débutant.
Qu’est-ce qu’Ollama et à quoi sert-il ?
Ollama est un moteur d’exécution et de gestion de modèles d’intelligence artificielle. Il simplifie plusieurs opérations normalement techniques : téléchargement des poids, chargement du modèle, quantification, utilisation du processeur graphique et exposition d’une API locale.
Il ne faut donc pas confondre Ollama et un modèle d’IA. Ollama est le logiciel qui fait fonctionner des modèles comme Gemma, Qwen, Llama, Mistral ou différents modèles spécialisés dans la programmation, la vision et les embeddings.
Ollama peut servir à créer un assistant privé, un outil de rédaction, un système de recherche documentaire, un agent de programmation ou une API interne.
Il prend également en charge les embeddings nécessaires aux systèmes de recherche augmentée par génération, plus connus sous le nom de RAG.
Comment fonctionne Ollama ?
Lors d’une utilisation locale, les fichiers du modèle sont téléchargés sur l’ordinateur. Les calculs nécessaires à la génération sont ensuite effectués par le processeur, le GPU ou les deux.
L’utilisateur peut démarrer un modèle depuis le terminal :
ollama run gemma4
Il peut aussi envoyer des requêtes à l’API native d’Ollama :
Ollama propose également une compatibilité avec plusieurs points d’accès de l’API OpenAI. Une application initialement conçue pour OpenAI peut ainsi parfois fonctionner avec un modèle local en changeant principalement l’adresse du serveur.
Cette compatibilité reste néanmoins partielle. Il faut vérifier les paramètres, formats de sortie et fonctions réellement pris en charge avant de migrer une application professionnelle.
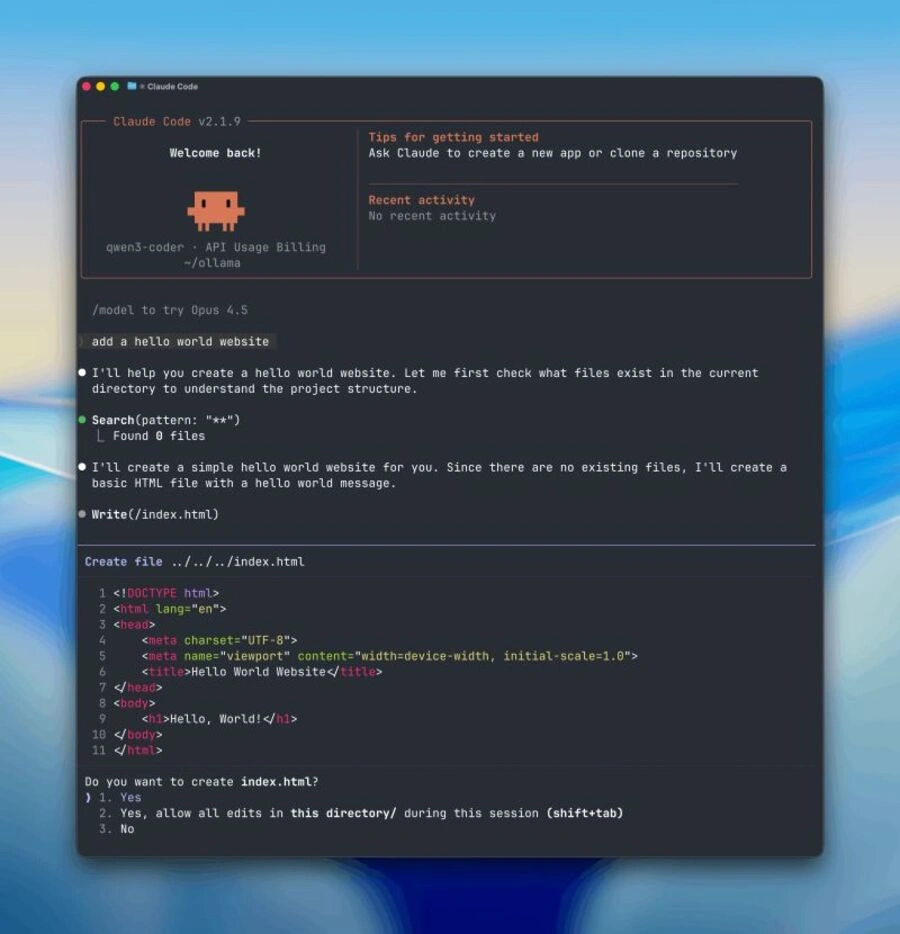
Depuis 2026, Ollama propose aussi une compatibilité avec l’API Messages d’Anthropic. Cela facilite notamment l’utilisation de modèles locaux ou cloud avec des outils comme Claude Code.
Ollama est-il simple à installer ?
Ollama fonctionne officiellement sur Windows, macOS et Linux. Une image Docker officielle est également proposée.
Après l’installation, lancer la commande ollama ouvre un menu interactif permettant notamment de sélectionner un modèle ou de connecter différents outils. Pour un premier chat, quelques commandes suffisent.
L’expérience de démarrage est donc plus simple que celle d’un déploiement manuel basé directement sur PyTorch, Transformers ou llama.cpp.
Aucune compétence avancée n’est nécessaire pour :
🟢 installer Ollama ;
🟢 télécharger un modèle ;
🟢 démarrer une conversation ;
🟢 utiliser l’application de bureau.
Des connaissances techniques deviennent toutefois utiles pour configurer Docker, exposer une API sur le réseau, intégrer une base vectorielle ou optimiser l’utilisation de la mémoire graphique.
Le paradoxe d’Ollama est donc le suivant : le premier modèle se lance facilement, mais une infrastructure bien optimisée demande de l’expérience.
Test pratique d’Ollama : que vaut réellement l’expérience ?
Afin de ne pas inventer de chiffres de performance impossibles à généraliser, cette analyse se concentre sur le parcours d’utilisation, les intégrations disponibles et les limites reproductibles. La vitesse dépend fortement du modèle, de sa quantification, du système d’exploitation et du matériel.
1. Lancement d’un premier modèle
Le lancement est particulièrement fluide. Ollama télécharge automatiquement la version proposée dans sa bibliothèque, puis ouvre une session de discussion.
Cette simplicité évite à l’utilisateur de devoir rechercher manuellement un fichier GGUF, sélectionner un moteur compatible et configurer chaque paramètre avant le premier essai.
2. Changement de modèle
Passer d’un modèle généraliste à un modèle de programmation ou d’embeddings est également rapide. La bibliothèque officielle contient des familles comme Qwen 3.5, Gemma 4, Llama 4, Mistral et de nombreux modèles communautaires.
Les tailles disponibles sont très différentes. Certains petits modèles peuvent fonctionner sur une machine modeste, tandis qu’un modèle comme Llama 4 Scout représente déjà plusieurs dizaines de gigaoctets dans certaines quantifications.
3. Utilisation comme serveur local
L’API locale constitue l’un des principaux points forts d’Ollama. Elle permet de connecter un script Python, une extension, un système RAG, un outil d’automatisation ou une interface comme Open WebUI.
L’utilisateur peut ainsi remplacer un fournisseur distant dans certains prototypes ou avec des outils comme Hermes Agent ou Unsloth sans réécrire toute son application.
4. Intégration dans un environnement de développement
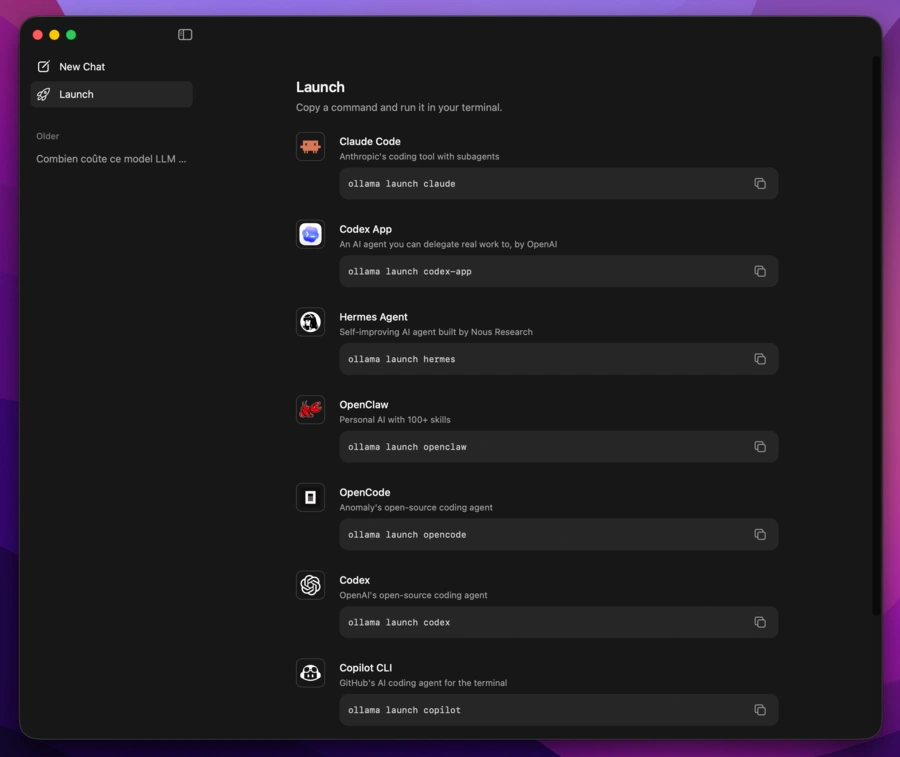
Ollama peut désormais faciliter la connexion avec des outils comme Claude Code, Codex, OpenCode, Hermes Agent ou différentes extensions de Visual Studio Code.
Pour un développeur, cette approche transforme Ollama en couche d’inférence commune : plusieurs applications peuvent utiliser les mêmes modèles téléchargés et le même serveur local.
5. Limite observée : le matériel reprend vite le contrôle
L’expérience reste excellente tant que le modèle tient confortablement dans la mémoire disponible. Lorsque les poids ou le cache de contexte débordent vers la mémoire système, la vitesse peut fortement diminuer.
Ollama permet de vérifier la répartition CPU/GPU avec la commande :
ollama ps
Un modèle chargé à 100 % sur le GPU sera généralement beaucoup plus réactif qu’un modèle partiellement ou entièrement exécuté sur le processeur.
Ollama est-il fait pour un usage local, cloud ou les deux ?
Ollama prend désormais en charge trois architectures distinctes. Cette distinction est indispensable pour comprendre la confidentialité, le coût et les performances.
Ollama en 2026 : exécution locale, cloud ou auto-hébergée
Architecture 🧩
Lieu d’exécution 🖥️
Confidentialité 🔐
Usage recommandé 🎯
🖥️ Ollama local
Ordinateur personnel ou station de travail de l’utilisateur
– Traitement directement sur la machine
– Protection élevée si le poste est sécurisé 🔒 Local
Documents sensibles, travail hors ligne et développement individuel
☁️ Ollama Cloud
Infrastructure distante administrée par Ollama
– Données traitées à distance
– Politique de conservation à vérifier avant utilisation
Grands modèles sans GPU local suffisamment puissant ☁️ Cloud
🛠️ Ollama auto-hébergé
Serveur privé, VPS ou infrastructure interne
Dépend du chiffrement, des accès et de l’isolation configurés
– API interne et serveur GPU partagé
– Déploiement contrôlé pour une équipe
Ollama en local
En fonctionnement local, Ollama indique ne pas recevoir les prompts ni les réponses. Une fois le modèle téléchargé, il est possible de l’utiliser sans connexion Internet, à condition de ne pas activer une fonction externe comme la recherche Web.[8]
Cette architecture représente le meilleur choix pour la confidentialité des données avec l’IA, les environnements isolés ou le traitement de documents internes.
Ollama Cloud
Les modèles cloud sont exécutés sur une infrastructure distante. Ils permettent d’accéder à des modèles trop volumineux pour un ordinateur personnel sans modifier complètement les outils déjà connectés à Ollama.
Selon l’éditeur, les prompts et réponses nécessaires au service sont traités, mais ne sont ni stockés, ni journalisés, ni utilisés pour entraîner les modèles. Des informations de compte et certaines métadonnées d’utilisation restent néanmoins collectées.[8]
Ollama sur son propre serveur cloud
Une entreprise peut également installer Ollama sur une machine GPU distante. Dans ce cas, le terme « cloud » ne désigne pas Ollama Cloud, mais une instance Ollama administrée par l’entreprise.
Cette option offre davantage de contrôle, mais oblige à gérer les accès, les correctifs, les sauvegardes, les journaux, le chiffrement et la disponibilité du service.
Quels modèles sont disponibles dans Ollama ?
La bibliothèque Ollama couvre plusieurs catégories de modèles.
Modèles Ollama à connaître en 2026 — bibliothèque vérifiée le 28 juin 2026
– Raisonnement, mathématiques et code
– Modèle ouvert orienté recherche
– Modèle 32B
– Variantes Instruct et Think
ollama run olmo-3.1:32b-instruct
Recherche reproductible et analyse approfondie des modèles ouverts
En juin 2026, la version 0.30.6 d’Ollama a notamment ajouté des poids Gemma 4 optimisés par quantification-aware training afin de réduire les besoins en mémoire.[9]
La disponibilité dans Ollama ne signifie toutefois pas que tous les modèles sont réellement open source au sens strict. Les poids, le code d’entraînement, les données et la licence peuvent être distribués selon des conditions différentes.
La licence d’Ollama est distincte de celle des modèles. Le cœur du projet Ollama est publié sous licence MIT, mais chaque modèle doit être contrôlé séparément avant un usage commercial.[10]
Ollama est-il plus performant que le cloud ?
La réponse dépend de la définition de la performance.
Ollama local peut être meilleur lorsque :
⚡ la latence réseau doit être supprimée
🔐 les données ne doivent pas quitter la machine
🔁 le volume d’utilisation est élevé et régulier
🧩 un petit modèle spécialisé suffit.
Une API cloud reste souvent meilleure lorsque :
🏆 la qualité maximale du modèle est prioritaire
📚 de très longs contextes sont nécessaires
👥 plusieurs utilisateurs travaillent simultanément
🛠️ aucune maintenance matérielle n’est souhaitée.
Un modèle local de 7B ou 14B ne devient pas automatiquement l’équivalent d’un modèle propriétaire de pointe parce qu’il fonctionne hors ligne. Ollama améliore le contrôle et l’accessibilité, mais ne supprime pas les écarts entre les modèles.
Des travaux comparatifs réalisés sur Apple Silicon ont d’ailleurs observé qu’Ollama privilégiait l’ergonomie développeur, tandis que des moteurs plus spécialisés pouvaient obtenir un meilleur débit ou un meilleur temps avant le premier token dans certaines configurations.
Ollama et confidentialité : les données sont-elles vraiment privées ?
La confidentialité des données Ollama est excellente lorsque le modèle fonctionne entièrement en local et que les fonctions cloud sont désactivées.
Ollama permet d’ailleurs de désactiver ses fonctionnalités cloud avec une configuration dédiée ou la variable suivante :
OLLAMA_NO_CLOUD=1
Cela désactive les modèles cloud et la recherche Web intégrée.
Confidentialité ne signifie pas absence de risques
Les conversations, journaux et modèles peuvent laisser des traces sur le disque. Une étude de criminalistique numérique publiée en 2026 a montré que les outils de LLM locaux pouvaient générer différents artefacts exploitables, notamment des historiques ou journaux selon l’application et la plateforme.
Les données ne partent donc pas nécessairement vers un fournisseur, mais elles doivent tout de même être protégées sur la machine.
Attention à l’exposition de l’API
Par défaut, Ollama écoute sur 127.0.0.1:11434, ce qui limite l’accès à l’ordinateur local. L’API locale ne demande pas d’authentification.
Exposer directement ce port sur un réseau ou Internet sans protection serait une mauvaise pratique. Une entreprise doit ajouter au minimum :
🔒 un mécanisme d’authentification
🧱 un pare-feu ou un réseau privé
🔐 un chiffrement TLS
📋 des restrictions d’accès et une journalisation maîtrisée.
Combien coûte Ollama ?
L’utilisation locale d’Ollama est gratuite. Le coût réel provient alors du matériel, du stockage, de l’électricité et du temps consacré à l’administration.
Ollama propose aussi des abonnements cloud.
Combien coûte Ollama en 2026 ? Tarifs locaux et abonnements cloud
Offre 🧩
Tarif affiché 💳
Principales caractéristiques ⚙️
À retenir 🔎
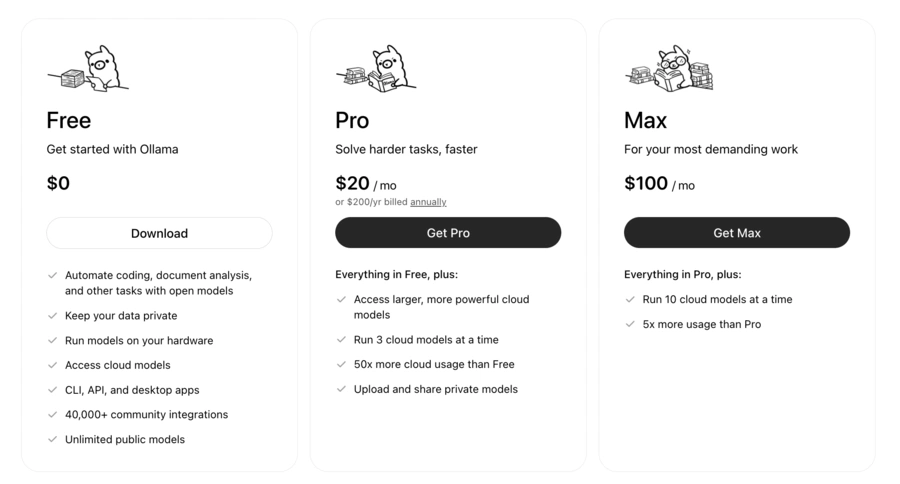
🆓 Free
💳 0 $/mois
– Exécution gratuite des modèles locaux
– Accès cloud limité, API et applications Ollama
– ✅ Idéal pour débuter et travailler hors ligne
– ⚠️ Matériel, stockage et électricité restent à financer
⭐ Pro
💳 20 $/mois
– Environ 50 fois plus d’usage cloud que Free
– Jusqu’à trois modèles cloud utilisés simultanément
✅ Adapté aux utilisateurs réguliers sans GPU local puissant
🚀 Max
💳 100 $/mois
– Environ cinq fois l’usage cloud du plan Pro
– Jusqu’à dix modèles cloud simultanés
✅ Conçu pour les usages intensifs et plusieurs workflows parallèles
🏢 Team
À venir
– Authentification SSO et administration centralisée
– Contrôle des modèles et support prioritaire
💡 Destiné aux équipes nécessitant gouvernance et gestion des accès
L’abonnement Pro est également affiché à 200 dollars par an lorsqu’il est payé annuellement.[16]
Ollama ne publie pas nécessairement un nombre fixe de tokens pour chaque niveau directement dans cette grille. Les mentions relatives à des multiplicateurs d’usage sont donc moins transparentes qu’une tarification classique au million de tokens.
Le local est-il réellement moins cher ?
Pour un usage fréquent, un ordinateur déjà équipé d’un GPU peut produire un coût marginal Ollama très faible. Il n’existe alors aucune facturation pour chaque requête locale.
Pour une utilisation occasionnelle, acheter une carte graphique uniquement pour faire fonctionner un LLM peut être moins rentable qu’une API cloud. Il faut aussi intégrer l’électricité, les mises à jour et le renouvellement matériel.
Avantages et inconvénients d’Ollama
Avantages et inconvénients d’Ollama en 2026
Critère 🧭
Avantages ✅
Inconvénients ⚠️
Confidentialité
Exécution locale et utilisation possible hors ligne 🔐 Local
La protection dépend de la sécurité de la machine
Installation
Installation rapide sur Windows, macOS et Linux
Le choix du modèle adapté au matériel reste parfois difficile
Intégrations
API simple et nombreuses connexions avec les outils IA
Compatibilité avec l’API OpenAI encore partielle
Coût d’utilisation
Aucun coût facturé par requête exécutée localement 💳 0 $/requête
Électricité, matériel et maintenance restent à financer
Catalogue de modèles
Large choix de modèles pour le code, le RAG et la vision
Les fichiers peuvent occuper beaucoup d’espace disque
Déploiement
Conteneurisation Docker disponible pour isoler les environnements
Administration, supervision et sécurité nécessaires en production
Services cloud
Possibilité d’utiliser des modèles distants sans GPU puissant
Limites cloud moins lisibles qu’un quota de requêtes fixe
Quels avis les utilisateurs donnent-ils sur Ollama ?
Les retours communautaires sont globalement positifs sur trois éléments : la simplicité du démarrage, l’écosystème d’intégrations et la possibilité de construire rapidement une API locale.
De nombreux utilisateurs associent Ollama à Open WebUI pour obtenir une interface proche de ChatGPT, tout en conservant les modèles sur leur propre machine.
Les critiques se concentrent surtout sur quatre points :
🎮 détection ou exploitation irrégulière de certains GPU AMD
📉 régressions de performance après certaines versions
🧠 consommation élevée lors de l’augmentation du contexte
☁️ manque de précision sur certaines limites d’usage cloud.
Ces problèmes ne touchent pas toutes les configurations. Ils montrent cependant qu’Ollama reste un logiciel d’infrastructure évoluant rapidement, et non un service totalement transparent pour l’utilisateur.
Meilleures alternatives à Ollama
Meilleures alternatives à Ollama en 2026 : interface, serveur API et production
Alternative 🧩
Point fort ✨
Limite principale ⚠️
Idéale pour 👥
Verdict rapide 🔎
🖥️ LM Studio
– Interface graphique très aboutie
– Serveur API local intégré
Moins orienté terminal et automatisations avancées
Débutants et exploration visuelle des modèles
✅ Le choix le plus accessible avec une interface complète 🖥️ Sans code
🌐 Jan
Application open source proche de l’expérience ChatGPT
Écosystème et choix d’intégrations plus restreints
Assistant local simple et conversations privées
✅ Une alternative ouverte pour discuter avec ses modèles
📚 GPT4All
– Chat local facile à prendre en main
– Interrogation de documents personnels
Moins flexible pour construire une infrastructure personnalisée
Utilisateurs non techniques et recherche documentaire locale
✅ Pertinent pour les documents, moins pour l’orchestration
⚙️ llama.cpp
Contrôle fin, moteur léger et nombreuses optimisations matérielles
Configuration plus technique qu’une application prête à l’emploi
Déploiement embarqué, optimisation et matériel limité
✅ Le meilleur socle technique pour maîtriser l’inférence
🚀 vLLM
– Débit élevé sur GPU
– Traitement efficace de requêtes simultanées
Besoins matériels et exploitation plus complexes
API de production et services utilisés par plusieurs personnes
✅ Prioritaire pour servir des modèles à grande échelle ⚡ Haut débit
🧩 LocalAI
– API auto-hébergée compatible avec plusieurs usages
– Texte, image, audio et embeddings
Davantage de composants et paramètres à administrer
Plateforme IA polyvalente et infrastructure privée
✅ Plus complet qu’Ollama, mais aussi plus exigeant
✍️ KoboldCpp
Exécutable autonome optimisé pour la génération créative
Positionnement plus spécialisé que les serveurs généralistes
Écriture longue, narration et interfaces de l’écosystème Kobold
✅ Excellent pour la création, moins adapté aux API métier
Conclusion : notre avis final sur Ollama
Notre avis Ollama en 2026 est très positif pour les utilisateurs qui veulent reprendre le contrôle sur leurs modèles, leurs données et leurs coûts. Peu d’outils rendent l’exécution locale de l’IA aussi rapide à démarrer tout en proposant une API aussi facile à intégrer.
Ollama ne transforme cependant pas un ordinateur moyen en centre de calcul illimité. Les performances restent dépendantes de la VRAM, de la quantification, de la longueur du contexte et de la maturité des pilotes.
Pour un développeur, un maker ou une entreprise souhaitant prototyper une IA privée, Ollama constitue un excellent premier choix. Pour un débutant recherchant uniquement une interface visuelle, LM Studio ou Jan seront parfois plus confortables. Pour une infrastructure GPU multi-utilisateur à haut débit, vLLM mérite d’être évalué.
Notre recommandation : commencez par un petit modèle local adapté à votre matériel, mesurez la qualité sur vos propres tâches, puis passez au cloud ou à une infrastructure plus puissante uniquement lorsque le besoin est démontré.
Pour quels usages Ollama est-il le plus pertinent ?
1. Assistant documentaire privé
Ollama peut être associé à une base vectorielle et à un modèle d’embeddings pour interroger des contrats, notes, procédures ou documents internes.
Il convient particulièrement aux organisations qui ne souhaitent pas transférer leurs contenus vers un service externe.
2. Programmation et analyse de code
Les modèles spécialisés peuvent générer du code, expliquer un dépôt, produire des tests ou assister un agent de programmation.
Les intégrations OpenAI et Anthropic simplifient la connexion avec de nombreux outils déjà existants.
3. Génération de contenu
Ollama peut produire des plans, brouillons, résumés, descriptions ou variantes éditoriales sans coût par requête.
La qualité dépendra toutefois davantage du modèle choisi que d’Ollama lui-même.
4. Recherche et expérimentation
Les chercheurs et data scientists peuvent comparer des modèles, modifier certains paramètres et tester des architectures locales sans dépendre entièrement d’une API externe.
5. Applications métier internes
Une entreprise peut construire un assistant de support, un classificateur, un extracteur de données ou une API de traitement du langage naturel.
Ollama devient alors une brique d’infrastructure. Il ne remplace pas à lui seul les systèmes d’identité, de supervision, de gouvernance ou d’évaluation.
Ollama pour les entreprises : bonne ou mauvaise idée ?
Ollama est pertinent pour un prototype, une petite équipe ou un service interne à charge modérée. Il permet de tester rapidement une architecture et de reprendre le contrôle sur l’hébergement.
Pour une utilisation critique, plusieurs briques doivent être ajoutées.
Ollama en entreprise en 2026 : fonctions natives et compléments recommandés
Besoin d’entreprise 🏢
Inclus nativement 🔍
Complément recommandé 🛠️
🔐 Authentification locale
❌ Non
– Proxy sécurisé ou passerelle API
– Authentification avant tout accès réseau
📊 Supervision avancée
⚠️ Limitée
Prometheus, journaux centralisés et alertes opérationnelles
👥 Gestion des utilisateurs
Limitée
SSO, rôles et contrôle d’accès gérés en externe
⚖️ Contrôle des licences
Gestion manuelle
Registre interne des modèles et licences approuvés
🧪 Évaluation de la qualité
❌ Non
– Banc de tests reproductible
– Jeux d’évaluation adaptés aux usages métier
🔁 Haute disponibilité
🏗️ À construire
Réplication, équilibrage de charge et mécanisme de reprise
L’offre Team annoncée doit apporter certaines fonctions d’administration, mais elle était encore indiquée comme « à venir » au moment de cette analyse.[16]
Pour une API fortement sollicitée par de nombreux utilisateurs, une solution spécialisée comme vLLM peut être plus adaptée.
Problèmes fréquents avec Ollama et solutions possibles
Ollama utilise uniquement le processeur
Exécutez ollama ps afin de vérifier la colonne indiquant la répartition CPU/GPU.
Une incompatibilité de pilote, un modèle trop volumineux ou une mauvaise détection du GPU peut provoquer un chargement sur le processeur.
Le modèle est très lent
Choisissez un modèle plus petit ou une quantification plus légère. Réduisez également la fenêtre de contexte et fermez les applications qui occupent la VRAM.
Ollama manque de mémoire
Le modèle, le cache de contexte et les autres applications se partagent la mémoire disponible. Une fenêtre de contexte très longue peut provoquer une saturation même lorsque les poids du modèle tiennent normalement en mémoire.
Les réponses sont de mauvaise qualité
Ollama n’est pas nécessairement responsable. Essayez un autre modèle, vérifiez son modèle de prompt, sa quantification et son adéquation avec la langue ou la tâche.
L’interface paraît trop limitée
L’application officielle couvre désormais les usages de base. Pour une interface plus riche, Open WebUI, LM Studio, Jan ou une application métier peuvent être plus adaptés.
Ollama est-il le meilleur choix pour votre cas d’usage ?
Ollama est-il le meilleur choix pour votre cas d’usage en 2026 ?
Votre priorité 🎯
Meilleur choix probable 🏆
Pourquoi le choisir ✨
Point de vigilance ⚠️
IA privée sur votre ordinateur
Ollama 🔐 Local
Exécution hors ligne et données conservées sur la machine
La confidentialité dépend aussi de la sécurité du poste
Interface graphique très simple
LM Studio ou Jan
Installation visuelle, catalogue intégré et conversations accessibles
Automatisations terminal moins centrales qu’avec Ollama
Intégration dans une application
Ollama 🔌 API locale
API simple pour connecter agents, scripts et interfaces
Compatibilité OpenAI partielle selon les fonctions utilisées
Serveur GPU à forte concurrence
vLLM ⚡ Haut débit
Débit élevé et gestion efficace des requêtes simultanées
Infrastructure GPU et exploitation plus exigeantes
Contrôle maximal de l’inférence
llama.cpp
Réglages fins, moteur léger et nombreuses optimisations matérielles
Configuration plus technique pour un utilisateur débutant
Chat documentaire sans configuration complexe
GPT4All
Importation simple de documents et recherche locale intégrée
Moins flexible pour construire une infrastructure personnalisée
Plateforme multimodale auto-hébergée
LocalAI
Réunit texte, image, audio et embeddings derrière une API
Davantage de composants à configurer et superviser
Écriture créative et univers Kobold
KoboldCpp
Expérience spécialisée pour la narration et les textes longs
Moins adapté aux intégrations métier généralistes
Ollama est probablement le meilleur choix lorsque vous recherchez une combinaison de simplicité, d’API locale, de confidentialité et de compatibilité avec de nombreux modèles.
Il est moins adapté lorsque vous avez besoin d’un service clé en main avec support contractuel, d’une interface sans aucune notion technique ou d’une infrastructure à très fort débit.
Quelles performances attendre d’Ollama ?
Il n’existe pas de score universel de performance Ollama. Deux utilisateurs exécutant le même modèle peuvent obtenir des résultats très différents selon leur GPU, la quantité de VRAM, la mémoire vive, le format de quantification et la longueur du contexte.
Le rôle du GPU
Un GPU compatible accélère considérablement la génération. Ollama prend notamment en charge différentes configurations NVIDIA, AMD et Apple Silicon, mais le niveau de maturité varie selon les plateformes.
Les configurations NVIDIA CUDA et Apple Silicon sont généralement plus prévisibles. Les utilisateurs de GPU AMD, en particulier sous Windows ou avec certaines puces intégrées, rapportent davantage de problèmes de détection, d’offloading ou de régression après une mise à jour.[11]
La mémoire disponible
Les repères suivants sont des ordres de grandeur et non des garanties.
Ollama en 2026 : quelle mémoire prévoir selon la taille du modèle ?
Configuration 🖥️
Modèles envisageables 🤖
Expérience probable 📊
Conseil pratique 💡
8 Go de RAM, sans GPU
Petits modèles quantifiés de 1B à 3B
Fonctionnel, mais lent et limité en contexte
Fermer les applications lourdes et privilégier la quantification 4 bits
16 Go de RAM
Modèles quantifiés de 3B à 8B
Chat, résumés et tests simples 🧠 16 Go
Choisir un modèle 4B ou 7B pour conserver de la fluidité
32 Go de RAM ou GPU adapté
Modèles de 7B à 14B, parfois davantage
Bon équilibre entre qualité, vitesse et polyvalence
Réserver assez de mémoire pour le système et le contexte
64 Go de RAM et plus
– Modèles plus volumineux
– RAG et fenêtres de contexte étendues
Usage avancé et traitements documentaires exigeants 📚 RAG
Surveiller la mémoire réellement consommée pendant l’inférence
GPU avec beaucoup de VRAM
Modèles lourds, contexte étendu et requêtes simultanées
Développement intensif avec réponses plus rapides
Privilégier une VRAM élevée pour charger le modèle sur le GPU ⚡ VRAM
Une grande fenêtre de contexte augmente fortement la consommation de mémoire. En 2026, Ollama adapte par défaut le contexte à la VRAM détectée : 4 000 tokens sous 24 Gio, 32 000 entre 24 et 48 Gio et 256 000 à partir de 48 Gio.[12]
Les agents et outils de programmation nécessitant beaucoup de contexte peuvent demander au moins 64 000 tokens. Une machine capable de lancer un modèle n’est donc pas forcément capable de l’utiliser confortablement avec un dépôt de code volumineux.
FAQ
Ollama est-il gratuit ?
Oui, Ollama peut être téléchargé et utilisé gratuitement pour exécuter des modèles sur votre propre matériel. Des abonnements payants sont proposés pour augmenter l’accès aux modèles cloud.
Ollama fonctionne-t-il sans Internet ?
Oui, après le téléchargement du logiciel et du modèle. Les modèles cloud, la recherche Web et le téléchargement de nouveaux modèles nécessitent toutefois une connexion.
Les données envoyées à Ollama restent-elles privées ?
Les requêtes exécutées localement restent sur la machine selon la documentation d’Ollama. Les modèles cloud traitent les requêtes à distance, avec une politique annoncée de non-rétention des prompts et réponses.
Ollama possède-t-il une interface graphique ?
Oui. Ollama propose désormais des applications de bureau et un menu interactif. Des interfaces externes comme Open WebUI restent plus riches pour certains usages.
Peut-on utiliser Ollama avec Docker ?
Oui. Une image Docker officielle est disponible, avec des configurations particulières pour l’accélération NVIDIA, AMD ou Vulkan selon le système.
Peut-on personnaliser un modèle dans Ollama ?
Oui. Les Modelfiles permettent notamment de définir un modèle de base, un message système et différents paramètres. Cette personnalisation ne constitue toutefois pas nécessairement un véritable fine-tuning des poids.
Ollama est-il adapté à la programmation ?
Oui. Il peut exécuter des modèles spécialisés dans le code et se connecter à différents agents ou environnements de développement.
Ollama remplace-t-il ChatGPT ou Claude ?
Il peut remplacer certaines fonctions de chat, de rédaction, de programmation ou d’analyse documentaire. La qualité finale dépend néanmoins du modèle utilisé et du matériel disponible.
TRANSPARENCE SUR LES PARTENARIATS Nous sélectionnons nos partenaires en fonction de leur qualité et fiabilité. Notre équipe les teste et les approuve indépendamment des accords commerciaux. Si vous achetez ou souscrivez via nos liens partenaires, nous pouvons recevoir une commission. Cela ne vous coûte rien de plus et aide à maintenir ce contenu gratuit. Pour en savoir plus, consultez notre engagement qualité.
.svg)
%20(1).png)