GPT-4 Vision (ou GPT-4V) est une révolution dans le domaine de l’intelligence artificielle, développée par OpenAI.
Ce modèle multimodal combine le traitement du langage naturel (NLP) et l’analyse d’images, permettant à l’IA de comprendre et de répondre à des requêtes basées sur du texte et des visuels. En 2026, avec une adoption massive dans plus de 1,5 million d’applications selon les dernières estimations d’OpenAI, GPT-4 Vision est un outil clé pour les innovations technologiques.
Qu’est-ce que GPT-4 Vision ?
GPT-4 Vision est une version avancée du modèle GPT-4, capable de traiter simultanément des images et du texte.
Contrairement aux modèles purement textuels, il peut analyser une image, en extraire des informations, et répondre à des questions contextuelles. Par exemple, il peut décrire une photo, lire du texte manuscrit, ou identifier des objets dans une scène complexe.
La multimodalité de GPT-4 Vision le rend unique : il simule une compréhension humaine en combinant vision et langage, ouvrant des possibilités dans des domaines comme l’accessibilité, l’éducation, ou encore l’analyse de données visuelles.
Comment fonctionne la reconnaissance d’image par GPT-4 Vision ?
Le fonctionnement de GPT-4 Vision repose sur une architecture hybride qui intègre plusieurs technologies :
Encodage visuel : Un encodeur visuel (inspiré de modèles comme CLIP) analyse l’image pour identifier des formes, objets, et textures.
Fusion texte-image : Les données visuelles sont combinées avec le texte via des transformateurs AI, permettant une compréhension unifiée.
Génération de réponse : Le modèle produit une sortie textuelle pertinente, comme une description ou une réponse à une question.
Technologies clés :
CLIP : Alignement texte-image pour contextualiser les visuels.
OCR avancé : Extraction de texte, y compris manuscrit, avec une meilleure précision accrue.
Apprentissage multimodal : Entraîné sur des milliards d’images et de textes pour une performance optimale.
Exemple : Soumettez une image d’une recette manuscrite, et GPT-4 Vision la transcrira en texte éditable.
Principaux cas d’utilisation de GPT-4 Vision
Voici des exemples concrets d’applications en 2026 :
🛠️ Cas d’Usage
🔎 Description
📌 Exemple concret
Accessibilité
Description en temps réel d’images pour malvoyants via lunettes connectées
Ask Envision + Google Glass fournit des descriptions en direct
Éducation
Analyse interactive de diagrammes et œuvres d’art avec explications détaillées
Plateformes e-learning décryptent schémas et étapes de processus visuels
E-commerce
Génération automatique de descriptions produits à partir de photos
Boutiques en ligne créent fiches produit enrichies (attributs, textures)
Santé
Analyse préliminaire d’images médicales (rayons X, IRM) avant validation humaine
Hôpitaux assistent radiologues pour identifier des lésions
Sécurité
Détection d’objets et anomalies dans flux vidéo en temps réel
Systèmes de surveillance urbaine signalent comportements suspects instantanément
Contrôle qualité (industrie)
Identification automatique de défauts sur lignes de production
Usines détectent rayures et malfaçons en continu pour réduire les rebuts
L’ajout de la réponse en temps réel permet à GPT-4 Vision de traiter des vidéos, utilisé par exemple dans la surveillance ou les assistants virtuels.
Comment intégrer GPT-4 Vision via l’API ?
L’intégration de GPT-4 Vision est accessible via l’API OpenAI. Voici un tutoriel rapide :
Prérequis : Inscrivez-vous sur platform.openai.com pour obtenir une clé API.
Choix du modèle : Utilisez gpt-4-vision-preview (ou une version plus récente en 2026).
• Très rapide (< 1 s par inference)
• Plug-&-play sur CPU
• Moins adapté aux tâches complexes
• Pas d’apprentissage continu intégré
Recommandation : Pour des prototypes rapides, LLaVA est idéal ; pour des projets exigeants, GPT-4 Vision reste supérieur.
Conclusion
GPT-4 Vision redéfinit l’IA en 2026 grâce à sa capacité à fusionner texte et image, offrant des solutions pour l’accessibilité, l’éducation, ou encore l’analyse en temps réel. Facile à intégrer via l’API OpenAI, il est puissant mais nécessite une attention aux limites comme les biais ou la précision.
Les alternatives open source, bien que prometteuses, n’égalent pas encore sa polyvalence. Explorez dès maintenant ses possibilités pour rester à la pointe de l’innovation !
Capacités Clés de GPT-4 Vision
Entrées visuelles : La principale caractéristique de GPT-4 Vision nouvellement sorti est qu'il peut désormais accepter du contenu visuel tel que des photographies, des captures d'écran et des documents et effectuer une variété de tâches.
Détection et analyse d'objets : Le modèle peut identifier et fournir des informations sur les objets dans les images.
Analyse de données : GPT-4 Vision est compétent pour interpréter et analyser des données présentées sous des formats visuels tels que des graphiques, des diagrammes et d'autres visualisations de données.
Déchiffrement de texte : Le modèle est capable de lire et d'interpréter des notes manuscrites et du texte dans les images.
Le modèle GPT-4V est construit sur les capacités existantes de GPT-4, offrant une analyse visuelle en plus des fonctionnalités d'interaction textuelle qui existent aujourd'hui.
Prise en Main : Démarrer avec GPT-4 Vision
GPT-4 Vision est actuellement (en octobre 2023) disponible uniquement pour les utilisateurs de ChatGPT Plus et Enterprise.
ChatGPT Plus coûte 20 $/mois, que vous pouvez mettre à niveau à partir de vos comptes ChatGPT réguliers gratuits.
Si vous êtes complètement nouveau sur ChatGPT, voici comment accéder à GPT-4 Vision :
Visitez le site web d'OpenAI ChatGPT et inscrivez-vous pour créer un compte.
Connectez-vous à votre compte et naviguez vers l'option "Mettre à niveau vers Plus".
Suivez la mise à niveau pour accéder à ChatGPT Plus (Note : c'est un abonnement mensuel de 20 $)
Sélectionnez "GPT-4" comme votre modèle dans la fenêtre de chat, comme indiqué dans le diagramme ci-dessous.
Cliquez sur l'icône de l'image pour télécharger l'image, et ajoutez un prompt demandant à GPT-4 de l'exécuter.
Dans le monde de l'IA, cette tâche est connue sous le nom de détection d'objets très utile dans le cadre de nombreux projets comme celui bien connu de la voiture autonome.
Voyons dès maintenant quelques exemples concrets.
Exemples et Cas d'Utilisation Réels de GPT-4 Vision
Maintenant que nous avons compris ses capacités, étendons-les à certaines applications pratiques dans l'industrie :
1. Recherche académique
L'intégration de GPT-4 Vision de la modélisation avancée du langage avec des capacités visuelles ouvre de nouvelles possibilités dans les domaines académiques, en particulier dans le déchiffrement de manuscrits historiques.
Cette tâche a traditionnellement été une entreprise minutieuse et chronophage menée par des paléographes et historiens qualifiés.
2. Développement web
Le GPT-4 Vision peut écrire du code pour un site Web lorsqu'il est fourni avec une image visuelle du design requis.
Il passe d'un design visuel au code source pour un site Web.
Cette capacité unique du modèle peut considérablement réduire le temps pris pour construire des sites Web.
De même, il peut être utilisé pour comprendre rapidement ce que signifie un bout de code à des fins scolaires ou d'ingénierie :
3. Interprétation des données
Le modèle est capable d'analyser des visualisations de données pour interpréter les données sous-jacentes et fournir des informations clés basées sur les visualisations.
4. Création de contenu créatif
Avec l'avènement de ChatGPT, les réseaux sociaux sont remplis de diverses techniques d'ingénierie de prompt, et beaucoup ont trouvé des moyens surprenants et créatifs d'utiliser la technologie générative à leur avantage.
Par exemple avec la sortie récentes des GPTs, il est désormais possible d'intégrer la fonction de GPT-4V à n'importe quel processus automatisé.
Limitations et Gestion des Risques de GPT-4 Vision
Il y a une dernière chose dont vous devez être conscient avant d'utiliser GPT-4 Vision dans des cas d'utilisation - les limitations et les risques associés.
Précision et fiabilité : Bien que le modèle GPT-4 représente des progrès significatifs vers la fiabilité et la précision, ce n'est pas toujours le cas.
Préoccupations de confidentialité et de biais : Selon OpenAI, de manière similaire à ses prédécesseurs, GPT-4 Vision continue de renforcer les biais sociaux et les visions du monde.
Restreint pour des tâches à risque : GPT-4 Vision est incapable de répondre à des questions demandant d'identifier des individus spécifiques dans une image.
Conclusion
Ce tutoriel vous a fourni une introduction complète au modèle GPT-4 Vision nouvellement sorti. Vous avez également été mis en garde sur les limitations et les risques que le modèle pose, et comprenez maintenant comment et quand utiliser le modèle.
La façon la plus pratique de maîtriser la nouvelle technologie est de mettre la main dessus et d'expérimenter en fournissant divers prompts pour évaluer ses capacités, et avec le temps, vous vous sentirez plus à l'aise avec.
Bien que cela soit un outil relativement nouveau et âgé d'un mois, il est construit sur les principes des Modèles de Langage à Grande Échelle et de GPT-4
Pose une question sur tes pages, comptes rendus et bases. Notion AI fait ressortir les décisions, les blocages et les prochaines actions qui méritent ton attention.
Des réponses IA sont offertes à tous. Le plan Business n'est requis qu'une fois ce quota épuisé.
Ouvre le compte rendu que tu repousses. Demande à Notion AI un brief décisionnel à lire en une minute.
.svg)



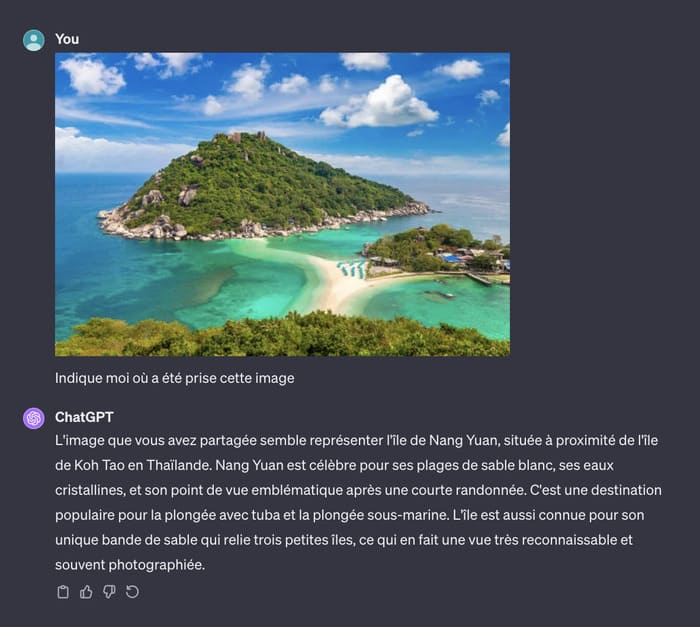







%25252520(1).avif)