.svg)




Introduction : Quand la spécialisation révolutionne l'intelligence artificielle
Dans le domaine de l'intelligence artificielle, une question fondamentale se pose : comment créer des modèles à la fois puissants et efficaces ? La réponse pourrait bien résider dans le Mixture of Experts (MoE), une architecture révolutionnaire qui applique le principe de spécialisation aux réseaux de neurones.
Imaginez une entreprise où chaque employé serait expert dans un domaine précis : comptabilité, marketing, développement technique. Plutôt que d'avoir des généralistes traitant toutes les tâches, cette organisation mobilise l'expert le plus pertinent selon le besoin. C'est exactement le principe du MoE : diviser un modèle massif en sous-réseaux spécialisés, appelés "experts", qui ne s'activent que lorsque leurs compétences sont requises.
Cette approche transforme radicalement notre conception des grands modèles de langage (LLMs) et ouvre la voie à une nouvelle génération d'IA plus efficiente et scalable.
Fondements théoriques : L'architecture qui révolutionne l'IA
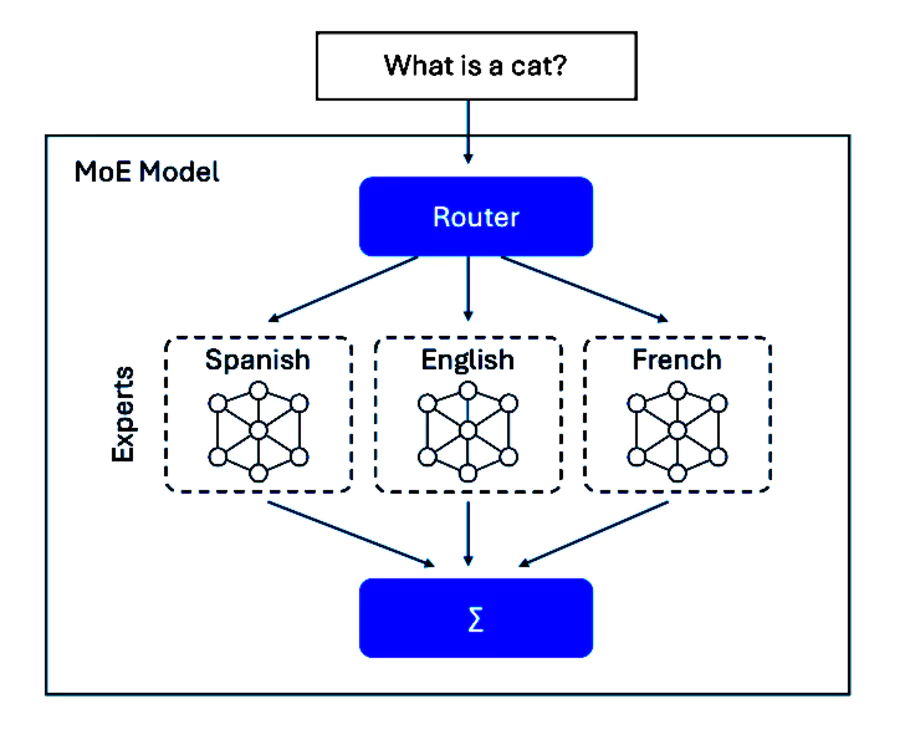
Qu'est-ce que le Mixture of Experts en intelligence artificielle ?
Le Mixture of Experts est une architecture de machine learning qui combine plusieurs sous-modèles spécialisés, appelés "experts", pour traiter différents aspects d'une tâche complexe. Contrairement aux modèles monolithiques traditionnels où tous les paramètres sont activés pour chaque prédiction, le MoE n'active qu'un sous-ensemble d'experts selon le contexte d'entrée.
Les composantes fondamentales
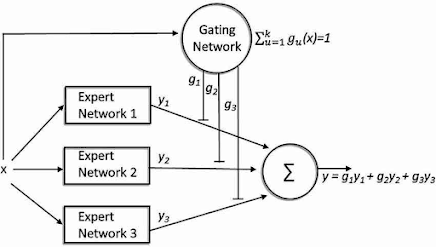
1. Les Experts

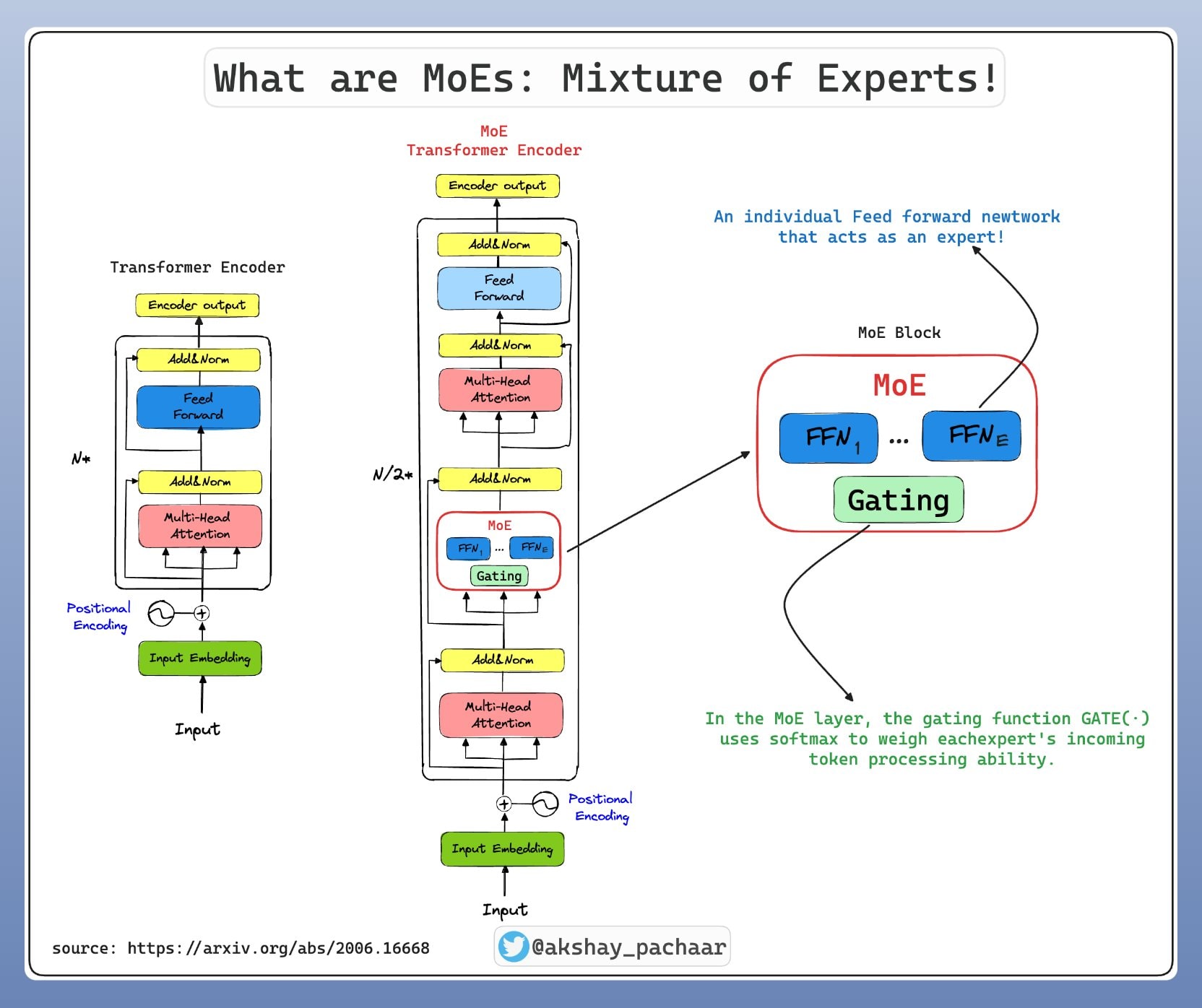
Chaque expert est un réseau de neurones spécialisé, typiquement constitué de couches Feed-Forward Networks (FFN). Dans un modèle Transformer utilisant MoE, ces experts remplacent les couches FFN traditionnelles. Un modèle peut contenir de 8 à plusieurs milliers d'experts selon l'architecture.
2. Le Gating Network (Réseau de routage)
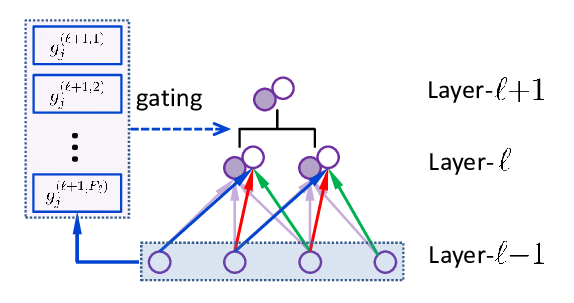
Le gating network joue le rôle de chef d'orchestre. Ce composant détermine quels experts activer pour chaque token d'entrée en calculant une probabilité d'activation pour chaque expert. Le mécanisme le plus courant est le top-k routing, où seuls les k experts avec les scores les plus élevés sont sélectionnés.
3. La Conditional Computation

Cette technique permet d'économiser drastiquement les ressources en n'activant qu'une fraction des paramètres totaux du modèle. Par exemple, dans un modèle avec 64 experts, seuls 2 ou 4 peuvent être activés simultanément, réduisant considérablement les coûts de calcul.
Architecture technique détaillée
Entrée (tokens)
↓
Self-Attention Layer
↓
Gating Network → Calcule les scores pour chaque expert
↓
Top-K Selection → Sélectionne les meilleurs experts
↓
Expert Networks → Traitement parallèle par les experts sélectionnés
↓
Weighted Combination → Combine les sorties selon les scores
↓
Sortie finale
Fonctionnement : Mécanismes de routage et spécialisation
Processus de routage intelligent

Le gating network utilise généralement une fonction softmax pour calculer les probabilités d'activation :
- Calcul des scores : Pour chaque token, le gating network génère un score pour chaque expert
- Sélection top-k : Seuls les k experts avec les scores les plus élevés sont retenus
- Normalisation : Les scores des experts sélectionnés sont renormalisés pour sommer à 1
- Traitement parallèle : Les experts choisis traitent simultanément l'entrée
- Agrégation pondérée : Les sorties sont combinées selon leurs scores respectifs
Mécanismes de load balancing
Un défi majeur du MoE est d'éviter que certains experts deviennent sous-utilisés tandis que d'autres sont surchargés. Plusieurs techniques assurent un load balancing efficace :
Auxiliary Loss Functions
Une fonction de perte auxiliaire encourage une distribution équilibrée du trafic entre experts :
Loss_auxiliary = α × coefficient_load_balancing × variance_distribution_experts
Noisy Top-K Gating
L'ajout de bruit gaussien aux scores d'experts pendant l'entraînement favorise l'exploration et évite la convergence prématurée vers un sous-ensemble d'experts.
Expert Capacity
Chaque expert dispose d'une capacité maximale de tokens qu'il peut traiter par batch, forçant une distribution du travail.
Spécialisations émergentes
Les experts développent spontanément des spécialisations durant l'entraînement :
- Experts syntaxiques : Spécialisés dans la grammaire et la structure
- Experts sémantiques : Focalisés sur le sens et le contexte
- Experts domaine-spécifiques : Dédiés à des domaines comme la médecine ou la finance
- Experts multilingues : Optimisés pour des langues particulières
Performance et optimisations

Techniques d'optimisation récentes
1. Hierarchical Mixtures of Experts
Architecture à plusieurs niveaux où un premier gating network route vers des groupes d'experts, puis un second niveau sélectionne l'expert final. Cette approche réduit la complexité de routage pour des modèles avec des milliers d'experts.
2. Expert Pruning dynamique
Élimination automatique des experts sous-performants pendant l'entraînement, optimisant l'architecture en temps réel.
3. Adaptive Expert Selection
Mécanismes d'apprentissage qui ajustent automatiquement le nombre d'experts activés selon la complexité de l'entrée.
Métriques de performance clés
| 📊 Métrique | 🧾 Description | 🎯 Objectif / Seuil recommandé | 💡 Interprétation & Actions (MoE Ops) |
|---|---|---|---|
| 👥 Expert Utilization | Proportion d’experts activés au moins une fois sur une fenêtre (batch / epoch); mesure la couverture des experts. | > 80 % des experts utilisés. | ✅ ≥80 % : couverture saine. ⚠️ 50–80 % : ajuster température / bruit du gate. ❌ <50 % : experts « morts » → augmenter load balancing loss ou appliquer expert dropout. |
| ⚖️ Load Balance Loss | Perte auxiliaire pénalisant la variance de fréquence d’activation entre experts (importance & load). Valeur proche de 0 = distribution équilibrée. | < 0.01 (après warm‑up). | 🔽 Si >0.01 : augmenter poids de la loss, activer techniques (importance + load), tester Similarity-Preserving / Global Balance. Trop élevé réduit qualité car gradients parasites. |
| 🎯 Router Efficiency | Taux de routages « utiles » : fraction des tokens dont l’expert top‑k produit un gain attendu (proxy : précision prédictive du routeur / F1 interne). | > 95 % (tokens correctement routés). | Si <95 % : affiner gate (température softmax, top‑k), réduire bruit, distiller vers un routeur plus simple; surveiller collisions (capacité saturée). |
| 🌱 Sparse Activation Ratio | Paramètres effectivement utilisés ÷ paramètres totaux (par token). Indique sparsité opérationnelle. | < 10 % (souvent 5–15 % selon k et #experts). | Si ratio ↑ : réduire k, augmenter #experts ou appliquer gating plus strict; si ratio trop bas (<3 %) risque sous‑apprentissage de certains experts → relâcher régularisation. |
| 📈 Expert Load Variance | Variance (ou coefficient de variation) du nombre de tokens par expert sur une fenêtre. | CV < 0.1 (ou variance normalisée faible). | Déséquilibre → ré‑initialiser gate pour experts inactifs ou activer techniques de global load balancing; surveiller saturation de quelques GPU. |
| 🧮 Capacity Factor Usage | Taux d’occupation des « slots » d’experts (tokens traités / capacité théorique par step). | 70–95 % (éviter 100 % constant). | <70 % : capacité gaspillée → augmenter batch ou réduire capacité factor. ≈100 % : risque de tokens rejetés / reroutés → augmenter capacité. |
| 🛑 Dropped Tokens Rate | Pourcentage de tokens non servis par leur expert prévu (overflow / capacity overflow). | < 0.1 % | Si élevé : augmenter capacity factor, équilibrer gate, appliquer expert-choice gating. |
| 🔁 Gate Entropy | Entropie moyenne des distributions de scores du gate (importance). Mesure diversité de sélection. | Plage « médiane » stable (ni trop basse ni trop haute). | Trop basse → collap se sur quelques experts; augmenter bruit / température. Trop haute → routage bruité; réduire noise / appliquer similarity-preserving loss. |
| 🧪 Router Precision (Proxy) | Précision prédictive d’un modèle supervisé reproduisant le gate (audit). Sert à estimer la cohérence du routage. | > 70–75 % (observé sur Mixtral/OpenMoE) | Si basse : gate instable; revoir régularisation, vérifier drift des embeddings d’entrée. |
| ⏱️ Latence / Token (P50/P90) | Temps moyen et percentile élevé de décodage par token. | P90 ≤ 2× P50; stabilité sous charge. | Explosion P90 → déséquilibre ou contention réseau (all‑to‑all); optimiser placement experts / parallelisme. |
| 🔋 FLOPs Effectifs / Token | FLOPs réellement consommés vs dense équivalent. | Gain ≥ 40 % vs dense cible | Gain faible → sur‑activation (k trop grand) ou overhead communication trop élevé. |
| 🧠 Specialization Score | Divergence inter‑experts des distributions d’activations / attention. | Divergence > baseline aléatoire | Divergence faible → experts redondants; appliquer auxiliary diversity loss ou ré‑initialiser experts inactifs. |
Implémentation pratique

Frameworks et outils
1. Hugging Face Transformers
Support natif des modèles MoE avec des APIs simplifiées :
from transformers import MixtralForCausalLM, AutoTokenizer
model = MixtralForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
2. FairScale et DeepSpeed
Frameworks spécialisés dans l'entraînement distribué de modèles MoE massifs.
3. JAX et Flax
Solutions haute performance pour la recherche et le développement d'architectures MoE innovantes.
Bonnes pratiques d'implémentation
1. Initialisation des experts
- Initialisation diverse pour éviter la convergence prématurée
- Pré-entraînement des experts sur des sous-domaines spécifiques
2. Stratégies de fine-tuning
- Gel sélectif d'experts pendant le fine-tuning
- Adaptation des mécanismes de routage pour de nouveaux domaines
3. Monitoring et debugging
- Surveillance continue de l'utilisation des experts
- Métriques de qualité du routage
- Détection précoce des déséquilibres
Comparaison avec les architectures alternatives
MoE vs Modèles denses
| 🧩 Aspect | 🧱 Modèles denses | 🔀 Modèles MoE | 💡 Explication / Impact rapide |
|---|---|---|---|
| ⚙️ Paramètres actifs / token | 100 % des poids calculés à chaque étape | ~5–20 % (ex. top‑2 experts sur 8) | 🔽 Moins de FLOPs par token côté MoE → efficacité & coûts réduits |
| 🚀 Latence d’inférence | Augmente avec la taille totale | ≈ latence d’un modèle de la taille « active » | ⏱️ MoE = qualité d’un grand modèle avec vitesse d’un moyen |
| 📦 Capacité totale (paramètres) | Doit payer chaque paramètre à l’exécution | Capacité « dormante » (experts inactifs par token) | 🧠 MoE empile de la connaissance sans coût linéaire d’inférence |
| 💾 Mémoire GPU (poids) | Tous les poids chargés & utilisés | Tous les experts chargés, fraction calculée | 📌 Gain compute oui, gain mémoire partiel seulement |
| 🔋 Énergie / token | Plus élevée (tous multiplications) | –40 à –60 % d’opérations | 🌱 MoE réduit OPEX & empreinte carbone à qualité équivalente |
| 📈 Scalabilité | Rendements décroissants (bande passante, VRAM) | Ajout d’experts modulaires | 🧗 MoE scale vers trillions de paramètres « potentiels » |
| 🎯 Spécialisation | Un bloc généraliste; fine‑tune global | Experts par langue / domaine | 🪄 MoE améliore niches sans dégrader tâches générales |
| 🧭 Routage | Chemin fixe | Gate choisit k experts/token | 🗺️ Allocation dynamique du calcul selon le contenu |
| 📜 Contexte long | Coût ∝ taille × longueur | Seulement experts actifs facturés | 📚 MoE absorbe mieux les prompts très longs |
| 🏁 Efficacité paramétrique | Performance = paramètres utilisés = coût | Performance > paramètres actifs | 🎯 MoE ≈ dense beaucoup plus grand (ex. 12B actifs ≈ 60–70B dense) |
| 🛠️ Complexité entraînement | Pipeline & tooling matures | Équilibrage charge, experts « morts » | ⚠️ MoE demande monitoring (load balance, entropy gating) |
| 🔄 Mises à jour | Retrain / LoRA global | Ajouter / remplacer un expert | ♻️ MoE itère plus finement sur nouvelles compétences |
| 🧩 Personnalisation client | Fine‑tuning complet coûteux | Tuning de quelques experts | 🏷️ MoE réduit temps & coût de personnalisation multi‑locataires |
| 🧪 Robustesse / Cohérence | Sorties homogènes | Variabilité inter‑experts | 🛡️ Nécessite calibration / distillation pour homogénéiser |
| ⚠️ Risques spécifiques | Coût/énergie explosent avec taille | Déséquilibre d’usage des experts | 📊 Surveiller distribution appels experts (load imbalance) |
| 💰 Coût inference (€/1M tokens) | Plus élevé à qualité cible | –30 à –50 % (selon k et overhead) | 💹 MoE optimise coût par qualité |
| 🔐 Isolation / multi‑locataires | Difficile (poids partagés) | Experts dédiés possibles | 🪺 Meilleure segmentation sécurité/compliance |
| 🧾 Exemples 2026 | GPT‑4.x, Claude 4, Llama 3.1, Phi‑3 | Mixtral, Grok‑1, DeepSeek V3, Qwen MoE | 🆚 Choix = simplicité stable vs capacité efficace |
| 🎯 Cas d’usage typiques | Production stable, exigences cohérence | Méga‑plateformes multi‑domaines, prompts longs | 🧭 Décision selon priorité: (stabilité) Dense | (coût+scaling) MoE |
| 📝 Résumé | Simplicité opérationnelle | Capacité + efficacité | ⚖️ Dense = gestion facile / MoE = performance-économie extensible |
MoE vs autres techniques de sparsité
Pruning structuré
- Avantage MoE : Sparsité apprise automatiquement
- Avantage Pruning : Simplicité d'implémentation
Knowledge Distillation
- Avantage MoE : Préservation des capacités du modèle
- Avantage Distillation : Réduction réelle de la taille du modèle
Défis éthiques

Biais et équité
Les experts peuvent développer des biais spécifiques à leurs domaines de spécialisation, nécessitant une attention particulière :
- Audit régulier des spécialisations émergentes
- Mécanismes de débiaisage au niveau du routage
- Diversité dans les données d'entraînement par expert
Transparence et explicabilité
Le routage dynamique complique l'interprétation des décisions du modèle :
- Logging détaillé des activations d'experts
- Outils de visualisation des patterns de routage
- Métriques d'explicabilité adaptées au MoE
Conclusion : L'avenir de l'IA distribuée
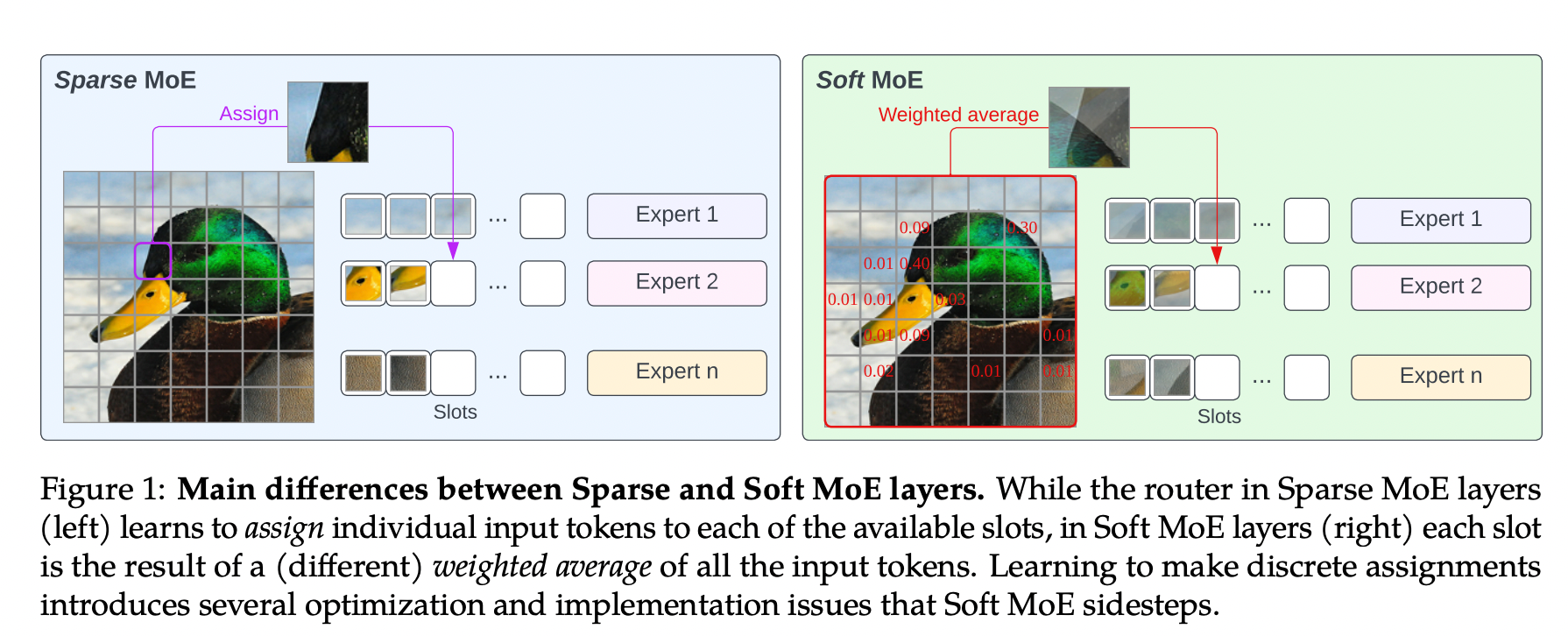
Le Mixture of Experts représente une évolution fondamentale dans l'architecture des modèles d'intelligence artificielle. En combinant efficience computationnelle, scalabilité et spécialisation automatique, cette approche ouvre la voie à une nouvelle génération de modèles plus puissants et plus accessibles.
Points clés à retenir
- Efficience révolutionnaire : Le MoE permet de multiplier par 10 la taille des modèles sans augmenter proportionnellement les coûts
- Spécialisation emergente : Les experts développent naturellement des compétences spécialisées
- Scalabilité sans limites : L'architecture s'adapte aux besoins croissants en taille de modèles
- Applications diverses : Du traitement du langage naturel à la vision par ordinateur
Perspectives d'avenir
L'évolution du MoE s'oriente vers :
- Architectures auto-adaptatives qui modifient leur structure selon les tâches
- Intégration multimodale native pour des systèmes d'IA plus polyvalents
- Optimisations hardware spécialisées pour maximiser l'efficience des routages
Le Mixture of Experts n'est pas simplement une optimisation technique : c'est une réinvention fondamentale de la façon dont nous concevons et déployons l'intelligence artificielle. Pour les chercheurs, ingénieurs et organisations souhaitant rester à la pointe de l'innovation IA, maîtriser cette technologie devient essentiel.
L'ère des modèles monolithiques touche à sa fin. L'avenir appartient aux architectures distribuées et spécialisées, où chaque expert contribue sa expertise unique à l'intelligence collective du système.
FAQ
Quelle est l'idée de base du MoE et comment ça révolutionne l'intelligence artificielle ?
L'idée est simple : au lieu d'activer tout un modèle pour chaque problème, on active seulement les experts pertinents. Cette approche transforme l'intelligence artificielle en permettant des réseaux neuronaux géants mais efficaces, où chaque expert traite des sous tâches spécifiques.
Comment le réseau de gating fonctionne-t-il pour router vers les bons experts ?
Le réseau de gating analyse votre entrée et calcule des scores pour déterminer quels experts sont les plus pertinents pour votre problème. Il combine ensuite les réponses des experts sélectionnés pour produire le résultat final.
Pourquoi l'efficacité du MoE est-elle supérieure aux petits modèles traditionnels ?
Le MoE offre une efficacité remarquable : il n'active que 10-20% de ses paramètres tout en maintenant les performances d'un modèle complet. Même les petits modèles MoE surpassent souvent des modèles denses plus volumineux.
GPT 4 et les grands modèles utilisent-ils cette technologie ?
Bien qu'OpenAI n'ait pas confirmé officiellement, de nombreux indices suggèrent que GPT 4 intègre des éléments MoE. Meta (Facebook) utilise cette architecture dans NLLB, et depuis mars 2024, Mixtral démocratise l'accès à ces technologies toute comme le modèle open source Kimi K2.
Comment passer de la lecture de cet article à la mise en œuvre pratique ?
Après cette lecture théorique, commencez par tester Mixtral 8x7B via Hugging Face. Ce guide pratique vous donnera les bases, puis explorez les frameworks spécialisés pour votre exécution spécifique.
Comment le MoE améliore-t-il la précision et l'apprentissage ?
La précision s'améliore car chaque expert se spécialise dans son domaine. SOn apprentissage se fait simultanément sur toutes les parties du système, créant une spécialisation naturelle qui booste les performances globales.
Quel avenir pour le MoE dans les prochaines années ?
L'avenir s'oriente vers la combinaison d'architectures auto-adaptatives, l'intégration multimodale native et l'optimisation pour les appareils mobiles. Cette technologie va démocratiser l'accès aux modèles d'IA (intelligence artificielle) puissants.