.svg)
Web Scraping expliqué : guide pratique. Technique d'extraction de données en ligne. Transformez votre analyse et veille avec le scraping web.

Le Web Scraping permet d'extraire des informations spécifiques à partir de sites web
Également appelé collecte automatisée de données, c'est une méthode innovante qui révolutionne la manière dont les entreprises récoltent et exploitent les données disponibles sur Internet (moteurs de recherche, réseaux sociaux, sites internet, etc..)

Le Web Scraping offre de nombreux avantages pour les entreprises :
En résumé, le Web Scraping est un atout précieux pour les entreprises, en particulier dans le domaine du Growth Hacking où la data joue un rôle central.
Le Web Scraping repose sur deux éléments clés : le Web Crawler et le Web Scraper.
Le Web Crawler et le Web Scraper forment un tandem efficace pour mener à bien vos projets de Web Scraping :
Cette combinaison puissante vous permet d'automatiser la collecte d'informations précises à grande échelle. Avec les bons outils et un paramétrage adéquat, vous serez en mesure d'exploiter toute la richesse des données présentes sur le Web pour booster votre activité.
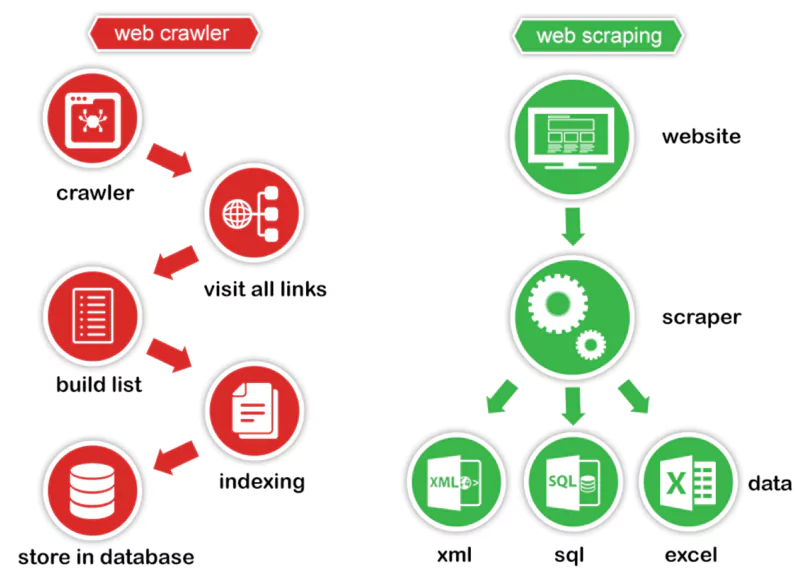
Aussi appelé "spider" ou "bot", le Web Crawler est un programme qui parcourt automatiquement Internet. Son rôle est de naviguer de page en page en suivant les liens, créant ainsi une vaste carte des URLs.
Voici comment il procède :
Au fil de son exploration, le Crawler indexe les données rencontrées. Il transmet ensuite au Web Scraper une liste organisée d'URLs à cibler pour l'extraction finale des informations pertinentes.
Une fois les pages web identifiées par le Crawler, le Web Scraper entre en jeu. Son objectif est d'extraire de ces pages les données spécifiques dont vous avez besoin : texte, images, prix, avis clients, etc.
Pour ce faire, le Scraper :
Un paramétrage fin du Web Scraper est essentiel pour obtenir des données fiables et cohérentes. Il doit pouvoir gérer les cas particuliers (valeurs manquantes, formats non-standard...) et s'adapter aux changements de structure des pages.
Le choix d'un outil de Web Scraping peut s'avérer complexe tant l'offre est pléthorique. Chaque solution a ses forces et ses faiblesses, et il est crucial de bien comprendre vos besoins avant de vous décider.
Pour vous aider dans cette tâche, nous avons passé au crible les outils incontournables du marché. Découvrez leurs avantages, leurs inconvénients et leurs tarifs pour faire votre choix en toute connaissance de cause.

Phantombuster est une suite d'outils automatisés permettant d'extraire des données et d'interagir avec les principaux sites web et réseaux sociaux. Grâce à ses "Phantoms" préconfigurés et sa console de code intégrée, il offre une grande flexibilité pour réaliser des tâches de scraping avancées sans infrastructure complexe.

👍 Avantages : Large bibliothèque de "Phantoms" prêts à l'emploi pour automatiser des tâches sur LinkedIn, Twitter, Instagram, Google... Possibilité de créer ses propres scripts d'automatisation en JavaScript. Intégration avec de nombreux outils tiers (Google Sheets, Slack, Zapier...). Excellent support client et communauté active.
👎 Inconvénients : Nécessite des connaissances en JavaScript pour créer des scripts personnalisés. Peut demander un certain temps de prise en main. Les actions automatisées doivent respecter les conditions d'utilisation des plateformes ciblées.

Octoparse est un outil de web scraping puissant qui allie simplicité d'utilisation et fonctionnalités avancées. Avec son interface glisser-déposer et ses options de configuration poussées, il permet de réaliser des projets d'extraction de données complexes sans compétences en programmation.
👍 Avantages :Interface graphique complète pour configurer tous les aspects d'un projet. Gestion des sites web dynamiques (avec rendu JavaScript). Pagination, macros et templates automatiques. Export et intégration des données dans le cloud.
👎 Inconvénients :Requiert un certain temps de prise en main. Peut se révéler coûteux pour des gros volumes.
BrightData (anciennement Luminati) est une plateforme de collecte de données web à très grande échelle. Avec son vaste réseau de proxies et ses outils automatisés, elle permet aux entreprises d'extraire rapidement d'importants volumes de données à partir de millions de sites web.
👍 Avantages :Collecte de données à très grande échelle grâce à un réseau de plus de 72 millions d'adresses IP. Rotation automatique des IP pour contourner les blocages. Intégration aisée via des SDK pour de nombreux langages (Python, JavaScript, PHP...). Outil de gestion de proxies intégré. Support technique réactif et disponible 24/7.
👎 Inconvénients :Tarification à l'usage pouvant devenir coûteuse pour de très gros volumes de données. Nécessite des compétences en développement pour tirer pleinement parti de la plateforme.

Parsehub est un outil de web scraping convivial qui permet d'extraire des données sans écrire une seule ligne de code. Grâce à son interface visuelle et ses fonctionnalités d'automatisation avancées, il rend le web scraping accessible à tous, même aux utilisateurs non techniques.

👍 Avantages :Interface visuelle intuitive de type "point-and-click". Aucune compétence en programmation requise. Idéal pour les projets simples ne nécessitant pas de setup complexe. Excellent support client.
👎 Inconvénients :Fonctionnalités limitées par rapport à des solutions code. Peu adapté aux projets complexes ou à grande échelle pour faire du web scraping.

BeautifulSoup est une bibliothèque Python permettant d'extraire facilement des données à partir de pages web. Grâce à sa simplicité d'utilisation et sa flexibilité, elle est devenue un choix populaire pour les développeurs souhaitant s'initier au web scraping.
👍 Avantages :Facilité de prise en main. Excellente documentation. Intégration aisée avec d'autres bibliothèques Python.
👎 Inconvénients :Peu adapté aux projets complexes nécessitant des fonctionnalités avancées. Nécessite des connaissances en Python.
EN SAVOIR PLUS >> Découvrir la bibliothèque BeautifulSoup dès maintenant
Scrapy est un framework Python puissant et complet pour l'extraction de données à grande échelle. Avec ses fonctionnalités avancées et son architecture extensible, il permet de développer rapidement des robots d'indexation (spiders) capables de gérer des volumes importants de pages web.
👍 Avantages :Gestion efficace des requêtes grâce à un système de files d'attente. Export des données dans de multiples formats (CSV, JSON, XML...). Architecture extensible via un système de middlewares et pipelines. Excellentes performances grâce à une gestion asynchrone.
👎 Inconvénients :Courbe d'apprentissage plus raide que BeautifulSoup. Installation et configuration peuvent être complexes.
EN SAVOIR PLUS >> Découvrir la bibliothèque Scrapy dès maintenant
Le Web Scraping peut cibler une vaste gamme de données disponibles sur Internet, en fonction des besoins spécifiques des utilisateurs. Voici quelques types de données fréquemment extraites :
Cette diversité de données rend le Web Scraping indispensable pour de nombreux secteurs, facilitant la prise de décision basée sur des données précises et actuelles.
Le web scraping est une technique puissante pour extraire des données à partir de sites web.
Selon vos besoins spécifiques et votre niveau de compétence, différents types de web scrapers peuvent être utilisés faire du web scraping.
Examinons les options disponibles pour vous aider à faire le choix le plus judicieux.

Ces outils sont conçus pour ceux qui nécessitent une solution entièrement personnalisée.
Utilisant des bibliothèques Python comme Scrapy ou BeautifulSoup, ils offrent une personnalisation sans limites pour s'adapter précisément à vos besoins.
Toutefois, ils requièrent des compétences en programmation et un engagement continu pour le développement et la maintenance.
Ces outils sont idéaux pour les développeurs ou les entreprises ayant des ressources en programmation qui recherchent une flexibilité totale dans leur stratégie de scraping.
Parfaits pour ceux qui ne possèdent pas de compétences techniques avancées, ces outils clé en main sont disponibles sous forme d'applications ou d'extensions de navigateur.
Ils facilitent la collecte de données grâce à des fonctionnalités telles que la planification automatique et l'exportation des données dans divers formats.
Adaptés aux individus, petites entreprises ou marketeurs, ces scrapers offrent une approche simple, avec une mise en œuvre rapide pour débuter avec le web scraping sans se soucier des copier coller manuels.

Les systèmes de scraping orientés IA représentent une évolution majeure dans le domaine.
Ces outils utilisent l'apprentissage automatique pour améliorer la collecte de données, permettant une identification plus précise des éléments à extraire et une adaptation en temps réel aux changements de structure des sites web.
Ils sont particulièrement utiles pour les grandes entreprises et les chercheurs qui nécessitent des données vastes et complexes pour alimenter des modèles d'IA.
Chaque type de web scraper a ses avantages et inconvénients, et le choix idéal dépendra de vos préférences personnelles, de votre niveau de compétence technique, et des exigences spécifiques de votre projet de collecte de données. Que vous soyez un utilisateur novice, un professionnel du marketing, ou un chercheur en IA, il existe un scraper adapté à vos besoins.
Le Web Scraping soulève des questions juridiques complexes notamment sur la propriété intellectuelle.
En effet, les données web appartiennent à leurs propriétaires respectifs, qui peuvent interdire ou limiter leur collecte via les conditions générales d'utilisation (CGU) et le fichier robots.txt. Certains sites vont même jusqu'à poursuivre en justice les entreprises qui scraperaient leurs données sans autorisation.
Pour rester dans la légalité, adoptez ces bonnes pratiques :
En respectant ces principes, vous pouvez profiter des avantages du Web Scraping tout en limitant les risques juridiques.
Le Web Scraping est un levier de croissance puissant pour de nombreuses entreprises. Voici quelques exemples inspirants d'applications concrètes :

Amazon, le géant du e-commerce, utilise le Web Scraping pour ajuster en temps réel ses prix par rapport à ceux de ses concurrents. Grâce à des outils qui analysent des millions de produits, Amazon s'assure de toujours proposer des tarifs compétitifs.
Expedia, le célèbre site de voyage, emploie le Web Scraping pour collecter des données sur les préférences de ses utilisateurs.
En analysant leurs recherches et leur historique de navigation, Expedia peut :

Les experts en référencement se servent du Web Scraping pour décortiquer les critères de classement de Google, tels que :
Ces données sont essentielles pour auditer et optimiser une stratégie SEO. En les collectant et en les analysant grâce au Web Scraping, les spécialistes du référencement peuvent identifier précisément les points forts et les axes d'amélioration d'un site web.

Si le Web Scraping offre de nombreuses opportunités, il doit toutefois s'adapter en permanence aux évolutions technologiques des sites web.
De plus en plus de sites utilisent des frameworks JavaScript comme Angular, React ou Vue.js pour générer dynamiquement leur contenu.
Les Web Scrapers doivent donc être capables d'exécuter le code JavaScript des pages pour accéder aux données.
Pour relever ce défi, des outils comme Puppeteer ou Selenium permettent d'automatiser un navigateur web et de simuler les actions d'un utilisateur réel. Ainsi, le Web Scraper peut charger le contenu dynamique et extraire les informations souhaitées.
Pour détecter et bloquer les robots, les sites web analysent de nombreux signaux :
Un Web Scraper doit donc imiter au mieux le comportement d'un utilisateur humain pour passer entre les mailles du filet. Cela implique d'introduire une certaine variabilité et une latence dans les requêtes, de simuler des actions utilisateur crédibles et de gérer intelligemment les cookies et autres données de session.
Le Web Scraping peut entraîner des blocages d'IP, des bannissements ou des poursuites judiciaires si les Conditions Générales d'Utilisation des sites sont violées.
Le Web Scraping est largement utilisé pour la surveillance concurrentielle, le suivi des prix, l'analyse des nouvelles, la génération de prospects et les études de marché.
Le Web Scraping est un outil puissant qui offre aux entreprises la possibilité de collecter des données précieuses à partir du Web pour divers usages tels que l'étude de marché, l'analyse des sentiments, le marketing par email et l'optimisation du référencement.
Cependant, malgré son utilité, le Web Scraping présente des défis tels que l'adaptation aux évolutions constantes des sites web, le contournement des systèmes de protection, et la garantie de la qualité des données collectées.
Il est donc primordial d'aborder ces défis avec une planification minutieuse, une connaissance approfondie des obstacles potentiels et une stratégie solide pour les surmonter.
Le Web Scraping est un processus complexe, mais avec une bonne préparation et un respect des règles, il peut s'avérer être un atout inestimable pour votre entreprise.










