.svg)
Discover the best free alternatives to Zapier for automation. A detailed comparison of tools that can streamline your workflows.

Web Scraping makes it possible to extract specific information from websites
Also called automated data collection, it is an innovative method that is revolutionizing the way in which companies collect and use data available on the Internet (search engines, social networks, websites, etc.)

Web Scraping offers a number of benefits for businesses:
In summary, Web Scraping is a valuable asset for businesses, especially in the field of Growth Hacking where data plays a central role.
Web Scraping is based on two key elements: the Web Crawler and the Web Scraper.
The Web Crawler and the Web Scraper form an effective tandem to carry out your Web Scraping projects successfully:
This powerful combination allows you to automate the collection of accurate information at scale. With the right tools and the right settings, you will be in a position to exploit all the wealth of data on the Web to boost your business.
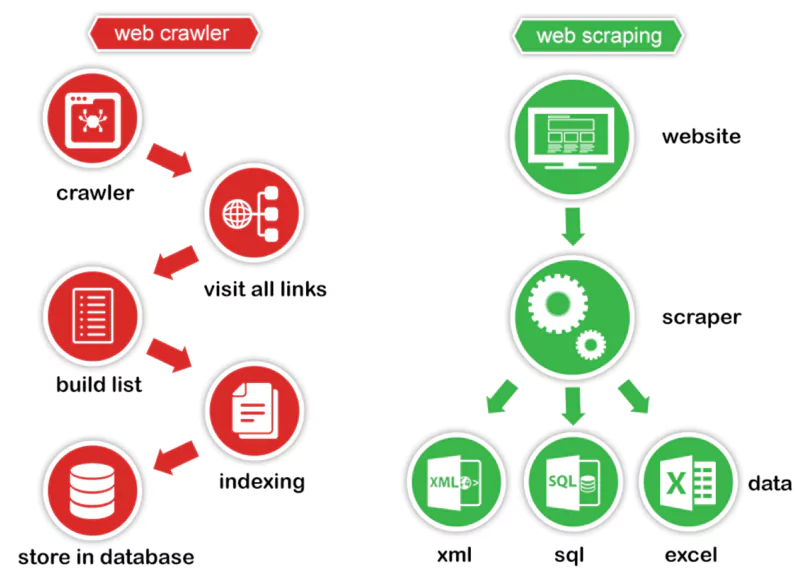
Also called a “spider” or “bot”, the Web Crawler is a program that automatically scans the Internet. Its role is to navigate from page to page by following the links, thus creating a vast map of URLs.
Here is how it does it:
As it explores, the Crawler indexes the data encountered. It then sends the Web Scraper an organized list of URLs to be targeted for the final extraction of relevant information.
Once the web pages are identified by the Crawler, the Web Scraper comes into play. Its objective is to extract from these pages the specific data you need: text, images, prices, customer reviews, etc.
To do this, the Scraper:
Fine tuning of the Web Scraper is essential to obtain reliable and consistent data. It must be able to manage specific cases (missing values, non-standard formats, etc.) and adapt to changes in page structure.
Choosing a Web Scraping tool can be complex as the offer is plethora. Each solution has strengths and weaknesses, and it's crucial to fully understand your needs before deciding.
To help you in this task, we have sifted through the essential tools on the market. Discover their advantages, disadvantages and prices so you can make an informed choice.

Phantombuster is a suite of automated tools for extracting data and interacting with major websites and social networks. Thanks to its preconfigured “Phantoms” and its integrated code console, it offers great flexibility to perform advanced scraping tasks without complex infrastructure.

👍 Pros : Large library of ready-to-use “Phantoms” to automate tasks on LinkedIn, Twitter, Instagram, Google... Possibility to create your own automation scripts in JavaScript. Integration with numerous third-party tools (Google Sheets, Slack, Zapier...). Great customer support and an active community.
👎 Cons : Requires JavaScript knowledge to create custom scripts. May take some time to get started. Automated actions must respect the terms of use of the targeted platforms.

Octoparse is a powerful web scraping tool that combines ease of use and advanced features. With its drag-and-drop interface and advanced configuration options, it allows complex data extraction projects to be carried out without programming skills.
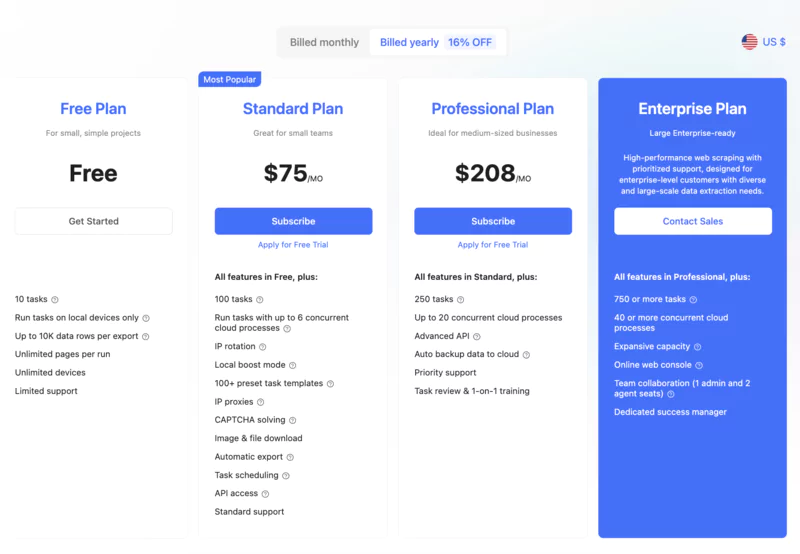
👍 Pros :Complete graphical interface to configure all aspects of a project. Management of dynamic websites (with JavaScript rendering). Automatic pagination, macros, and templates. Export and integration of data in the cloud.
👎 Cons :Requires some time to get started. Can be expensive for large volumes.
BrightData (formerly Luminati) is a very large-scale web data collection platform. With its vast proxy network and automated tools, it allows businesses to quickly extract large volumes of data from millions of websites.
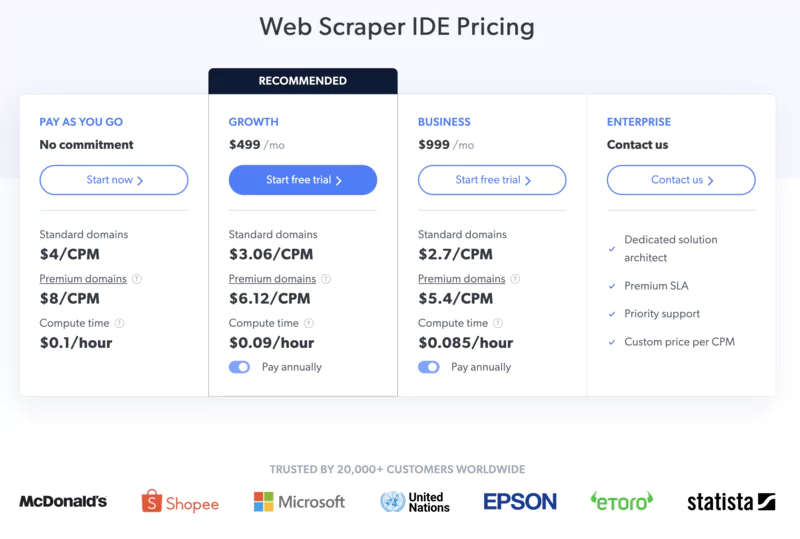
👍 Pros :Very large-scale data collection thanks to a network of more than 72 million IP addresses. Automatic IP rotation to bypass blocks. Easy integration via SDKs for many languages (Python, JavaScript, PHP...). Integrated proxy management tool. Responsive technical support available 24/7.
👎 Cons :Pay-per-use pricing that can become expensive for very large volumes of data. Requires development skills to take full advantage of the platform.

Parsehub is a user-friendly web scraping tool that allows you to extract data without writing a single line of code. Thanks to its visual interface and advanced automation features, it makes web scraping accessible to everyone, even non-technical users.

👍 Pros :Intuitive “point-and-click” visual interface. No programming skills required. Ideal for simple projects that don't require complex setups. Great customer support.
👎 Cons :Limited functionalities compared to code solutions. Not very suitable for complex or large-scale projects for web scraping.

BeautifulSoup is a Python library that makes it easy to extract data from web pages. Thanks to its ease of use and flexibility, it has become a popular choice for developers who want to get started with web scraping.
👍 Pros :Easy to handle. Great documentation. Easy integration with other Python libraries.
👎 Cons :Not suitable for complex projects requiring advanced functionalities. Requires Python knowledge.
LEARN MORE >> Discover the BeautifulSoup library now
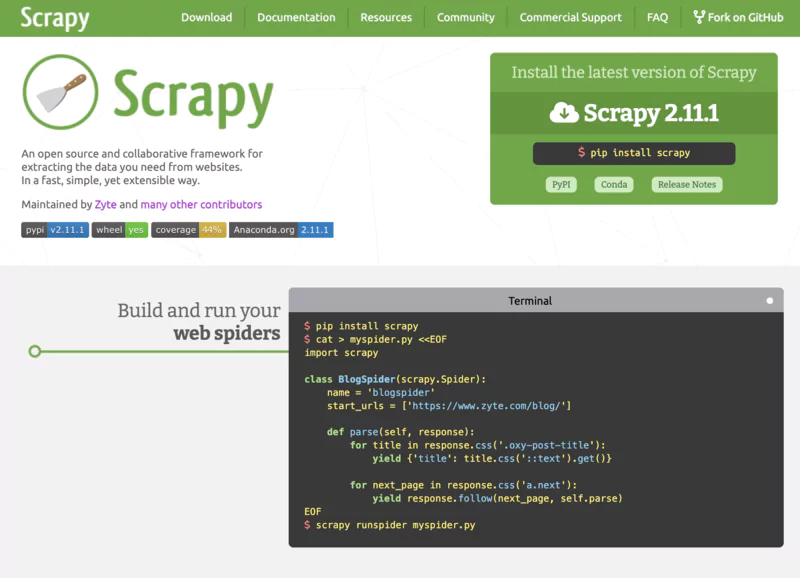
Scrapy is a powerful and comprehensive Python framework for extracting data at scale. With its advanced functionalities and its extensible architecture, it allows the rapid development of indexing robots (spiders) capable of managing large volumes of web pages.
👍 Pros :Efficient management of requests thanks to a queue system. Data export in multiple formats (CSV, JSON, XML...). Extensible architecture via a middleware system and pipelines. Excellent performance thanks to asynchronous management.
👎 Cons :Steeper learning curve than BeautifulSoup. Installation and configuration can be complex.
LEARN MORE >> Discover the Scrapy library now
Web Scraping can target a wide range of data available on the Internet, based on the specific needs of users. Here are some of the types of data that are frequently retrieved:
This diversity of data makes Web Scraping indispensable for many sectors, facilitating decision-making based on accurate and current data.
Web scraping is a powerful technique for extracting data from websites.
Depending on your specific needs and skill level, different types of web scrapers can be used to do web scraping.
Let's look at the options available to help you make the best choice.

These tools are designed for those who require a fully customized solution.
Using Python libraries like Scrapy or BeautifulSoup, they offer unlimited customization to adapt precisely to your needs.
However, they require programming skills and a continuous commitment to development and maintenance.
These tools are ideal for developers or businesses with programming resources who are looking for total flexibility in their scraping strategy.
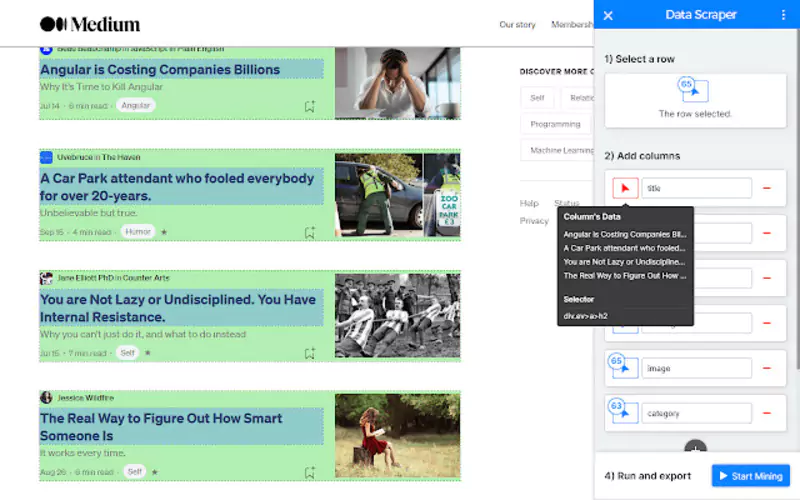
Perfect for those who don't have advanced technical skills, these turnkey tools are available as applications or browser extensions.
They facilitate data collection with features such as automatic scheduling and data export in a variety of formats.
Adapted to individuals, small businesses or marketers, these scrapers offer a simple approach, with a quick implementation to get started with web scraping without worrying about manual copy and paste.

AI-oriented scraping systems represent a major evolution in the field.
These tools use machine learning to improve data collection, allowing more precise identification of the elements to be extracted and adaptation in real time to changes in the structure of websites.
They are especially useful for large companies and researchers who require large and complex data to power AI models.
Each type of web scraper has its pros and cons, and the ideal choice will depend on your personal preferences, your level of technical skill, and the specific requirements of your data collection project. Whether you are a novice user, a marketing professional, or an AI researcher, there is a scraper to suit your needs.
Web Scraping raises complex legal questions, particularly concerning intellectual property.
Indeed, web data belongs to their respective owners, who can prohibit or limit their collection via the general conditions of use (CGU) and the robots.txt file. Some sites even go so far as to sue companies that scrape their data without authorization.
To stay legal, adopt these best practices:
By following these principles, you can enjoy the benefits of Web Scraping while limiting legal risks.
Web Scraping is a powerful growth driver for many businesses. Here are some inspiring examples of concrete applications:

Amazon, the e-commerce giant, uses Web Scraping to adjust its prices in real time compared to those of its competitors. Thanks to tools that analyze millions of products, Amazon ensures that it always offers competitive prices.
Expedia, the famous travel site, uses Web Scraping to collect data on the preferences of its users.
By analyzing their searches and browsing history, Expedia can:

SEO experts use Web Scraping to dissect Google's ranking criteria, such as:
This data is essential for auditing and optimizing an SEO strategy. By collecting and analyzing them through Web Scraping, SEO specialists can precisely identify the strengths and areas for improvement of a website.

While Web Scraping offers many opportunities, it must however constantly adapt to the technological evolutions of websites.
More and more sites are using JavaScript frameworks like Angular, React, or Vue.js to dynamically generate their content.
Web Scrapers must therefore be able to execute the JavaScript code of the pages to access the data.
To meet this challenge, tools like Puppeteer or Selenium make it possible to automate a web browser and simulate the actions of a real user. So, the Web Scraper can load dynamic content and extract the information you want.
To detect and block robots, websites analyze numerous signals:
A Web Scraper must therefore imitate the behavior of a human user as best as possible to get through the cracks. This involves introducing some variability and latency into requests, simulating credible user actions, and intelligently managing cookies and other session data.
Web Scraping may result in IP blocking, bans, or legal proceedings if the General Terms of Use of sites are violated.
Web Scraping is widely used for competitive monitoring, price tracking, news analysis, lead generation, and market research.
Web Scraping is a powerful tool that offers businesses the ability to collect valuable data from the web for a variety of uses such as market research, sentiment analysis, email marketing, and SEO optimization.
However, despite its usefulness, Web Scraping presents challenges such as adapting to the constant evolution of websites, bypassing protection systems, and ensuring the quality of the data collected.
It is therefore essential to approach these challenges with careful planning, a thorough understanding of potential obstacles, and a solid strategy for overcoming them.
Web Scraping is a complex process, but with the right preparation and compliance with the rules, it can be an invaluable asset for your business.










