
.svg)





Ethical Practices of Web Scraping
Scraping is not just about legality. It's also about respect: respect for people (data), the site (infrastructure), and the editorial work (content).

A good rule of thumb: if your extraction feels like a "silent copy" that disrupts the site or surprises users, you're already in a RISK zone.
How to scrape ethically?
- ✅ Use an official API when available (or an export/feed).
- ✅ Respect
robots.txt(it's not "the law," but it's a clear signal). - ✅ Read the Terms of Service and avoid explicitly prohibited uses.
- ✅ Maintain a reasonable pace (rate limit + pauses).
- ✅ Adopt an "audit-friendly" stance: purpose, minimization, traceability.
Why is it IMPORTANT?
- ✅ You reduce the risk of legal issues (contract/Terms of Service, personal data).
- ✅ You avoid technical blockages and "anti-bot" escalations.
- ✅ You protect your reputation (and that of your company).
- ✅ You keep cleaner and more stable data over time.
| Ethical Checklist 🧭 | OK ✅ | Caution ⚠️ | Red flag 🚫 |
|---|---|---|---|
| Page Access 🔓 | Access to public pages – Without technical bypass |
Gray areas (light paywalls) – Unclear usage restrictions |
Security bypass – Forced or unauthorized access |
| Collected Data 👤 | Non-personal data – Strictly necessary data |
Public personal data – Requires GDPR framework |
Sensitive or massive data – Profiling individuals |
| Server Load 🖥️ | Gentle call pace – Use of backoff |
Frequent request spikes – High volumes |
Obvious site overload – Hindrance to operation |
| Transparency 📣 | Displayed identity (User-Agent) – Clear contact + Logs |
Vague or generic identity – Difficult to trace origin |
Total IP disguise – Lack of traceability |
| Reuse ♻️ | Internal statistical analysis – Global aggregation |
Partial republication – Citations without agreement |
Complete database copy – Theft of protected content |
Common Techniques to Block Crawlers
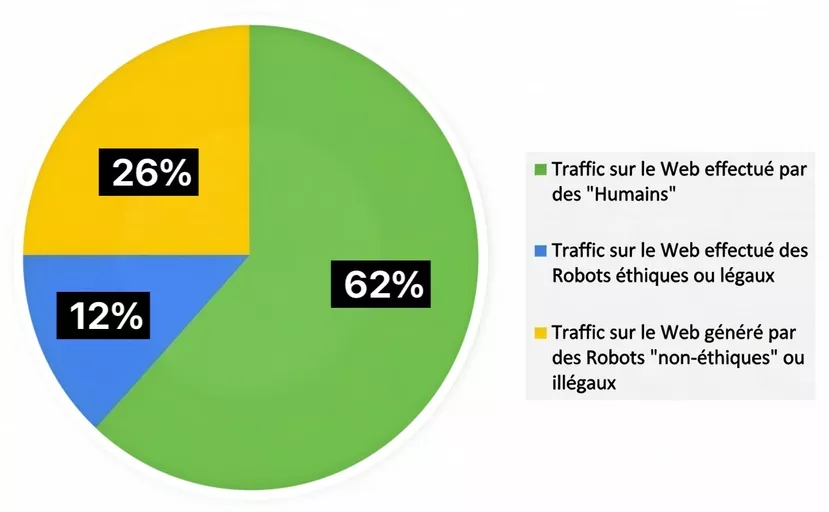
Sites don't "hate" scraping by principle. They protect themselves because automation can quickly become an issue of load, fraud, competition, or intellectual property.
Today, robots (good + bad) weigh heavily in traffic. An Imperva report indicates that automated traffic has surpassed human traffic and that "bad bots" represent a major part of internet traffic.
| Defense 🛡️ | Objective 🎯 | What it means for you 🧩 |
|---|---|---|
| Rate limiting / quotas ⏱️ | Prevent server resource saturation | – Need to slow down requests – Mandatory local caching – Drastic reduction of volume per session |
| CAPTCHA 🧩 | Block aggressive automation attempts | – Immediate stop signal (STOP) – Requalification of need via official API – Request for license or commercial agreement |
| IP / ASN Blocking 🌐 | Interrupt waves of suspicious requests | – Your behavior resembles an attack – Risk of being blacklisted – Need to review request sources |
| Behavioral Detection 🤖 | Identify non-human navigation patterns | – Need for a more sober crawl approach – Prioritize quality over technical stealth – Avoid predictable repetitive patterns |
| Honeypots (Traps) 🪤 | Identify and trap malicious robots | – Risk of collecting corrupted data – Negative impact on your technical reputation – Evidence of unauthorized scraping for the target site |
Example: LinkedIn vs hiQ Labs (what it says… and what it DOESN'T say)

This case is often cited, but it concerns American law (CFAA) and doesn't apply "as is" to France/EU.
What we learn in practice:
- The court considered that scraping publicly accessible data didn't necessarily fall under the CFAA, even after a cease-and-desist, within the "authorization" debate.
- However, the risk doesn't disappear: contract/Terms of Service, copyright, and other grounds can still be relevant.
- The dispute ended with a confidential agreement (so no "total victory" usable as a universal rule).
The right takeaway: this type of case law mainly shows that "public" ≠ "free of all," and that platforms also defend an economic stake (data, services, competition).
Why Prevent Web Scraping on Your Website?
From the publisher's side, there are very concrete reasons (often combined).
- ✅ Performance: too many requests can degrade the site, even causing incidents (some attacks rely on saturation).
- ✅ Security: automation is also used to test vulnerabilities, perform credential stuffing, or scrape endpoints.
- ✅ Competition: tracking prices, customers, product pages, features…
- ✅ "Semi-public" data: information accessible but not intended to be extracted on a large scale.
- ✅ Content: risk of copying without attribution, loss of value for the creator.
| Publisher Motivation 🏢 | Perceived Risk 😬 | Common Response 🔧 |
|---|---|---|
| Infrastructure Stability | – Risk of downtime – Explosion of infrastructure costs – Degradation of response times |
Implementation of Quotas – Deployment of WAF (Web Application Firewall) – Strict rate limiting |
| User Protection 👤 | – Exposure of personal profiles – Massive harvesting for spam – Violation of customer privacy |
Advanced CAPTCHA systems – Geographic or IP blocks – Update of Terms of Service rules |
| Business Protection 💼 | – Simple cloning of the service – Loss of competitive advantage – Decrease in advertising revenue |
Targeted contractual actions – Specific access restrictions – Database monitoring |
| Data Quality 🧼 | – Data scraped then distorted – Loss of control over the source – Obsolescence of disseminated information |
Opening of paid APIs – Licensing systems – Insertion of "trap" data (canaries) |
| Intellectual Property (IP) 🧠 | – Unauthorized copying of protected content – Reuse without attribution – Economic parasitism |
Automated duplicate detection – Legal actions – Technical content protection |
Common Challenges of Web Scraping
Scraping rarely "works" once and for all. The obstacles mainly come from the reality of the web: it changes, it loads, it protects itself.
1. Unstable HTML Structures
A site can change a selector and break your extraction overnight.
➡️ Solution: automated tests + monitoring + alert thresholds.
2. Continuous Maintenance
A scraper without maintenance quickly becomes a machine producing false data.
➡️ Solution: versioning, sample validation, error logs.
3. Anti-Bot Measures

CAPTCHA, honeypots, blockages: often a signal that you're exceeding a limit (technical or contractual).
➡️ Solution: slow down, reduce, or switch to API/license — not "harden" the bypass.
4. Authentication & Sessions
As soon as a login is required, you enter a more sensitive contractual and technical zone.
➡️ Solution: check authorizations, Terms of Service, and legal framework first.
5. Quality & Latency
Slow sites = partial content, timeouts, inconsistencies.
➡️ Solution: error recovery, quality control, progressive collection.
Web Scraping Tools: Overview and Precautions
Web scraping relies on a wide range of tools, from "ready-to-use" solutions to advanced programming libraries.
Depending on your technical level and goals, you can choose visual scraping software (like ParseHub, Octoparse), browser extensions, Python frameworks like BeautifulSoup or Scrapy, or specialized SaaS platforms for online data extraction:
| The Real Test 🎯 | What You Get 💎 | To Watch Out For ⚠️ | Real Fit 🧭 |
|---|---|---|---|
| ParseHub 🧲 |
Visual scraping “click → extract” 🖱️ Lists, records, quick exports (CSV/JSON) → You see the data drop… right away |
Dynamic sites = sometimes fragile 🧩 Page changes → selectors to redo → Plan a verification routine |
Beginner, occasional need 🚀 “I want to test an idea in 1 hour” → Without coding, without pipeline |
| Octoparse 🧰 |
Templates + scheduling ⏱️ Cloud possible for continuous running → Scraping becomes a small “job” |
Steeper learning curve 🧠 Quotas, limits, options according to plan → Read the grid before scaling |
SME, recurring extraction 📅 “I want the same data every week” → Without setting up a dev team |
| Chrome Extension 🧩 |
Ultra-fast capture of tables/lists ⚡ Perfect for simple pages, immediate exports → You go from page → Excel in 2 minutes |
Pagination + infinite scroll = trap 🪤 Little control over retries/logs → OK for “one-shot,” not for production |
Research, audit, validation 🔍 “I want a list now” → No need for architecture |
| BeautifulSoup (Python) 🍲 |
Clean and flexible HTML parsing 🐍 You control fields, cleaning, export → Perfect for “static” sites |
Must manage requests + throttling 🚦 Respect TOS/robots, GDPR minimization → Otherwise, you block yourself |
Light dev, custom need 🛠️ “I want to extract EXACTLY these elements” → And normalize them |
| Scrapy (Python) 🕸️ |
Scale crawl + pipelines + retries 📦 Logs, queues, scheduling… everything is planned → You switch to “serious collection” mode |
Longer setup, mandatory rigor 🧱 Storage, security, data governance → Otherwise, it quickly becomes uncontrollable |
Large volumes, multi-site collection 🏗️ “I want a reliable dataset” → With history and traceability |
| Playwright (Headless) 🎭 |
Modern JS sites, login, complex journeys 🧠 You “play” the page like a human → Where simple HTML fails |
Anti-bot, captchas, blockages 🧱 Higher machine cost, scripts to maintain → Plan a plan B |
SPA, dashboards, interactive pages 🖥️ “Content only exists after loading” → So browser automation |
| Compliance Checklist 🛡️ |
Data minimization ✂️ + clear purpose Logs & traceability 🧾 + limited retention → You can explain “why” and “how long” |
TOS/Terms of Service + intellectual property 📜 Personal data = GDPR (rights, security, access) 🔒 → “Tech” scraping without framework = risk |
Before the 1st run ✅ “I validate the framework, then automate” → Otherwise, you redo everything… later |
Before launching a data collection project, take the time to assess the risks related to data protection and intellectual property.
Ensure that the chosen tool offers filtering, log management, and data security features. Finally, keep in mind that web scraping can raise technical issues (blockages, captchas, changes in page structure) and legal ones: compliance must remain at the heart of your approach, both in the choice of tool and in the implementation of the collection.
Use Cases of Web Scraping
Web scraping can transform how businesses and professionals leverage data from the internet. Among the most common use cases are competitive intelligence, price monitoring, collecting customer reviews, analyzing trends on social media, or aggregating content for market studies. Public websites, e-commerce platforms, and social networks are full of valuable information that, once extracted, can fuel strategic analyses or optimize marketing campaigns.
In the field of big data and artificial intelligence, web scraping can be used to build massive databases to train models, detect weak signals, or automate decision-making. However, every data collection must be framed by respecting the terms of service of the targeted sites, and the protection of users' personal data must remain a top priority. Failure to comply with these rules can lead to legal issues, sanctions, or damage to reputation.
In summary, web scraping can offer a significant competitive advantage when used responsibly and in compliance with GDPR principles. Before launching a project, it is essential to clearly identify the objective, verify the legality of the collection, and implement measures to ensure the security and confidentiality of the extracted information.








