.svg)
How to scrape the web without getting blocked. Learn about browser fingerprinting, TLS fingerprinting, header hijacking, and how to avoid scraping detection.

When you open your browser and access a web page, it almost always means that you are requesting content from an HTTP server. One of the easiest ways to extract content from an HTTP server is to use a traditional command line tool such as cURL.
In fact, if you simply do: curl www.google.com, Google has plenty of ways of knowing you're not human (for example by looking at the headers). Headers are small pieces of information that accompany every HTTP request sent to the servers.
One of these pieces of information describes precisely the customer who made the request. This is the infamous “User-Agent” header. Just by looking at the “User-Agent” header, Google knows that you're using cURL.
If you want to know more about headers, the Mozilla page is excellent.
On an experimental basis, Go here. This web page simply shows the header information for your request.

Headers are easy to change with cURL, and copying the User-Agent header from a browser can do the trick. In the real world, you'll need to define more than one header.
But it is not difficult to artificially falsify an HTTP request with cURL or any other library to make the request look exactly like a request made with a browser.
Everyone knows that. So to determine if you're using a real browser, websites are going to check something that cURL and the library can't do: run Javascript code.
The concept is simple: the website embeds a Javascript snippet into its web page that, once executed, “unlocks” the web page.
If you're using a real browser, you won't notice the difference. If not, you will receive an HTML page containing an obscure Javascript code:

Again, this solution is not completely bulletproof, mainly because it is now very easy to run Javascript outside of a browser with Node.js.
However, the web has evolved and there are other tips to determine if you are using a real browser or not.
Trying to run Javascript snippets with Node.js is difficult and not very robust.
As soon as the website has a more complicated control system or it is a big application: cURL and the pseudo-JS execution with Node.js become useless.
So the best way to look like a real browser is to use one.
Les Headless browsers behave like a real browser, except you can easily use them programmatically. The most popular is Chrome Headless, a Chrome option that behaves just like Chrome without the entire user interface that surrounds it.
The easiest way to use Chrome Headless is to call a tool that packs all of the functionality into a simple API. Selenium and Puppeteer are the three most well known solutions.
However, this will not be enough, as websites now have tools that detect headless browsers. This arms race has been going on for a long time.
While these solutions may be easy to implement on your computer, running them on a large scale on remote servers can be trickier.
Managing a large number of headless Chrome instances is one of the many problems that tools like ScrapingBee can help you solve.
Everyone, especially font-end developers, knows that every browser behaves differently. Sometimes it's about CSS rendering, sometimes Javascript, and sometimes just internal properties.
Most of these differences are well known and it is now possible to detect whether a browser is who it claims to be. This means that the website is asking “whether all of the browser's properties and behaviors match what I know about the User Agent sent by this browser.”
That's why there's a relentless race between website scrapers who want to pretend to be a real browser and websites that want to tell the difference between headless and the rest.
However, in this race, web scrapers tend to have a considerable advantage, here's why:

Most of the time, when Javascript code tries to detect if it is running in non-display mode, it is because malicious software is trying to evade the behavioral fingerprint.
This means that Javascript code will perform well in an analytics environment and poorly in real browsers.
That is why theTeam behind Chrome Headless Mode strives to make it indistinguishable from a real user's web browser in order to prevent malicious software from doing so.
Indirectly, web scrapers benefit from this work tirelessly.
You should also know that while running 20 cURL in parallel is trivial and Chrome Headless is relatively easy to use for small use cases,.
However, it can be tricky to scale because it uses a lot of RAM: managing more than 20 instances is a challenge.
That's pretty much all you need to know about how to pretend you're using a real browser. Now let's see how to behave like a real human.
TLS is the abbreviation for Transport Layer Security and is the successor to SSL, which was actually the meaning of the “S” in HTTPS.
This protocol guarantees the confidentiality and integrity of data between two or more computer applications in communication (in our case, a web browser or a script and an HTTP server).
Like the browser fingerprint, the purpose of the TLS fingerprint is to uniquely identify users based on how they use TLS.
The operation of this protocol can be divided into two main parts.
Most of the data used to build the fingerprint comes from TLS verification, or at least what we call its “fingerprint.”
For information purposes, the parameters of a TLS fingerprint are as follows:
If you want to know what your TLS footprint is, I suggest you visit This website.
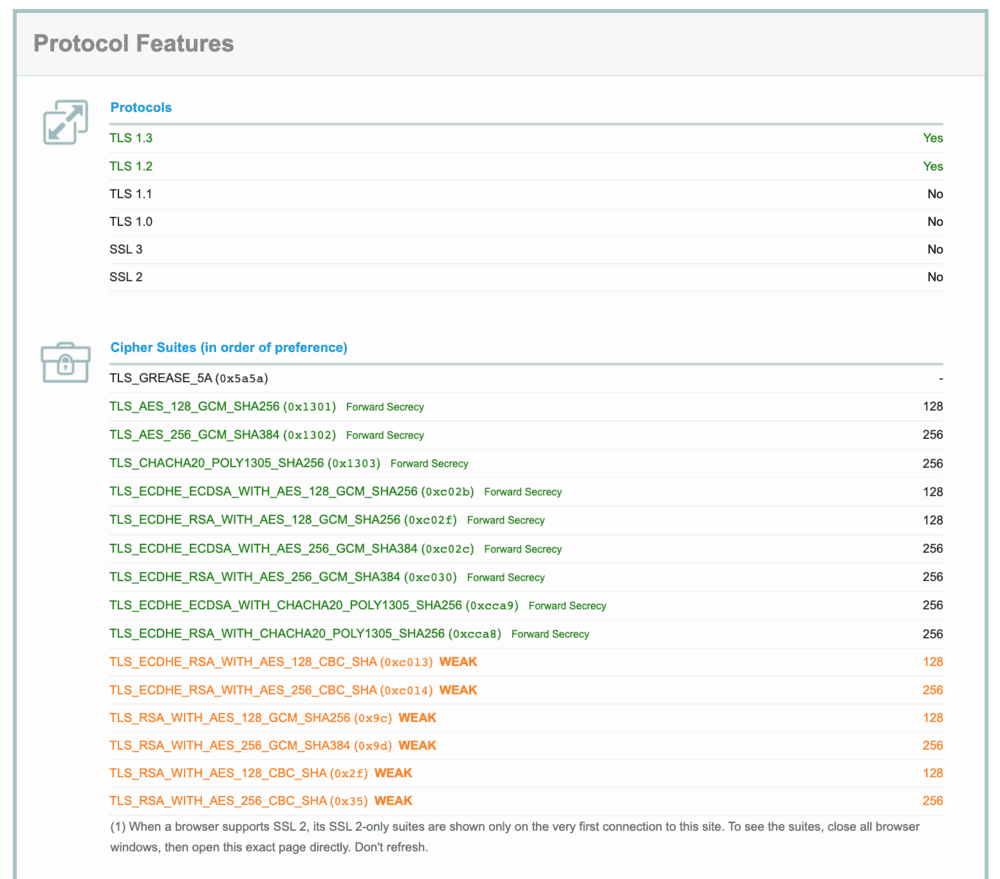
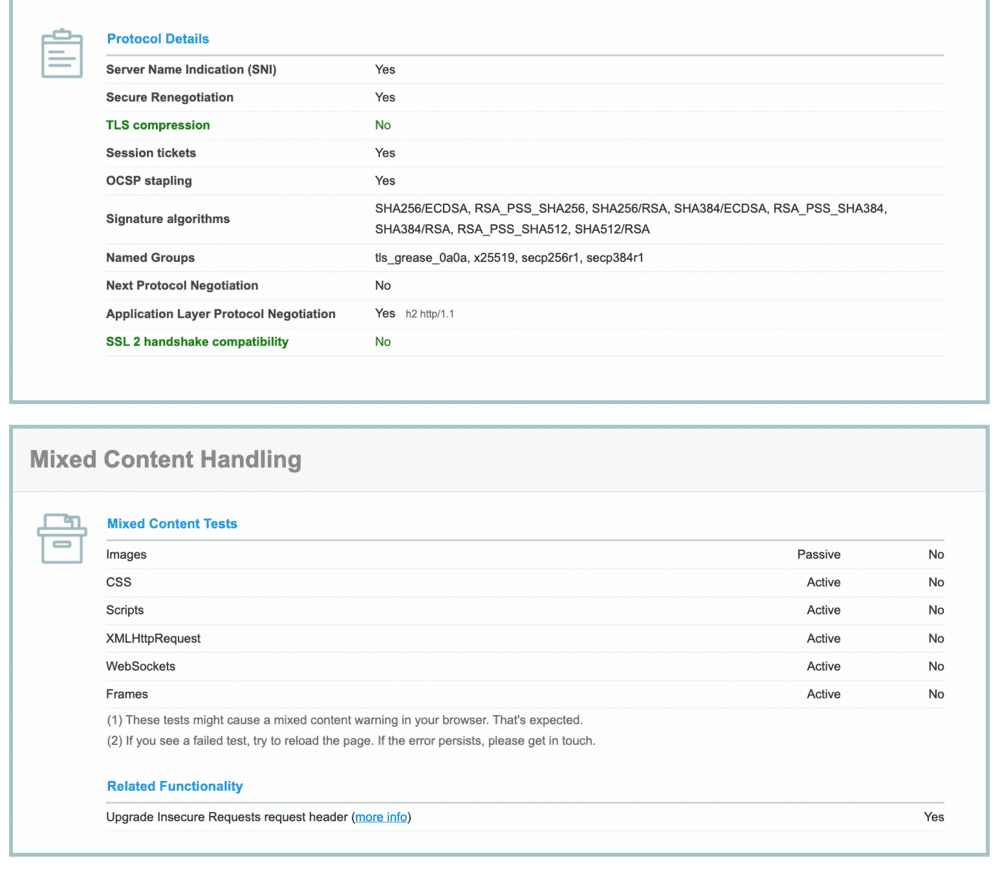
Ideally, you should change your TLS settings to increase your discretion when browsing the web. However, it is more difficult than it seems.
First of all, as it does not exist A lot ofTLS fingerprints, simply randomizing these parameters won't work. Your fingerprint will be so rare that it will be instantly flagged as fake.
Second, TLS settings are low-level items that rely heavily on system dependencies. So it is not easy to change them.
For example, the famous module Python requests does not allow you to change the TLS fingerprint.
Here are some resources for changing the TLS version and cipher suite to your preferred language:
Keep in mind that most of these libraries depend on your system's SSL and TLS implementation.
OpenSSL is the most used and you may need to change its version to completely change your fingerprint.
A human using a real browser will rarely request 20 pages per second from the same website.
So, if you want to request a lot of pages from the same website, you need to make the website believe that all of these requests come from different places in the world, that is, from different IP addresses.
In other words, you have to Use proxies.
Proxies are not very expensive: ~$1 per IP. However, if you need to make more than ~10k requests per day on the same website, costs can go up quickly, with hundreds of addresses required.
One thing to take into account is that proxy IPs need to be constantly monitored so that you can eliminate the one that no longer works and replace it.
There are several proxy solutions on the market, here are the most used rotating proxy providers such as:
There are also numerous lists of free proxies and I don't recommend using them because they're often slow and unreliable, and the websites offering these lists aren't always transparent about where these proxies are located.
Free proxy lists are generally public, and as a result, their IPs will automatically be banned by the most important website.
If you are interested (but not recommended) here is the site of Freeproxylist :
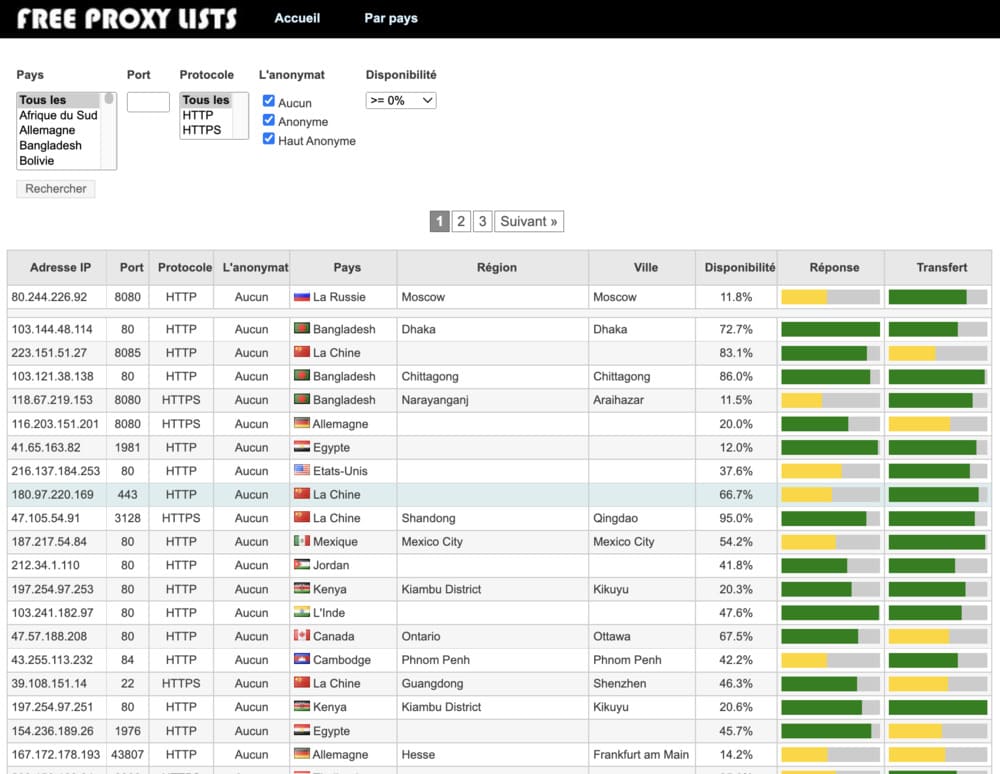
Proxy quality is important. Anti-crawling services are known to maintain an internal list of proxy IPs, so any traffic coming from these IPs will generally be blocked. Be careful to choose a reputable proxy. That's why I recommend using a paid proxy network or building your own.
Another type of proxy that you may want to consider is mobile, 3G, and 4G proxies. They are useful for scraping websites that are difficult to scrap in mobile mode, such as social networks.
ISP proxies are also very interesting because they combine the advantages of residential proxies with the speed of data centers.
To build your own proxy, you can take a look at Scrapoxy, a great open-source API that allows you to build a proxy API across different cloud providers.

Scrapoxy will create a proxy pool by creating instances on different cloud providers (AWS, OVH, Digital Ocean). Then, you can configure your client to use the Scrapoxy URL as the primary proxy, and Scrapoxy will automatically assign a proxy in the proxy pool.
Scrapoxy is easily customizable to adapt to your needs (rate limit, blacklist...) but can be a bit tedious to set up.
You can also use the TOR network, aka The Onion Router. It is a global computer network designed to route traffic through many different servers in order to disguise its origin.

Using TOR makes network monitoring and traffic analysis very difficult. There are numerous cases of use of TOR, such as privacy, freedom of expression, journalists in a dictatorial regime, and, of course, illegal activities.
In the context of web scraping, TOR can hide your IP address and change your robot's IP address every 10 minutes. The IP addresses of the TOR exit nodes are public.
Some websites block TOR traffic by applying a simple rule: if the server receives a request from one of TOR's public exit nodes, it blocks it.
.jpeg)
That's why, in many cases, TOR won't help you, compared to traditional proxies. It should be noted that traffic going through TOR is also inherently much slower due to multiple routing.
ISP proxies are also very interesting because they combine the benefits of residential proxies with the speed of data centers.
Sometimes the proxies are not enough. Some websites routinely ask you to confirm that you are human using what are called CAPTCHAs.
Most of the time, CAPTCHAs only show up for suspicious IPs, so changing the proxy will work in these cases. For other cases, you will need to use a CAPTCHAS resolution service (2 Captchas and DeathbyCaptchas come to mind).
While some Captchas can be resolved automatically using optical character recognition (OCR), the most recent one should be resolved by hand.
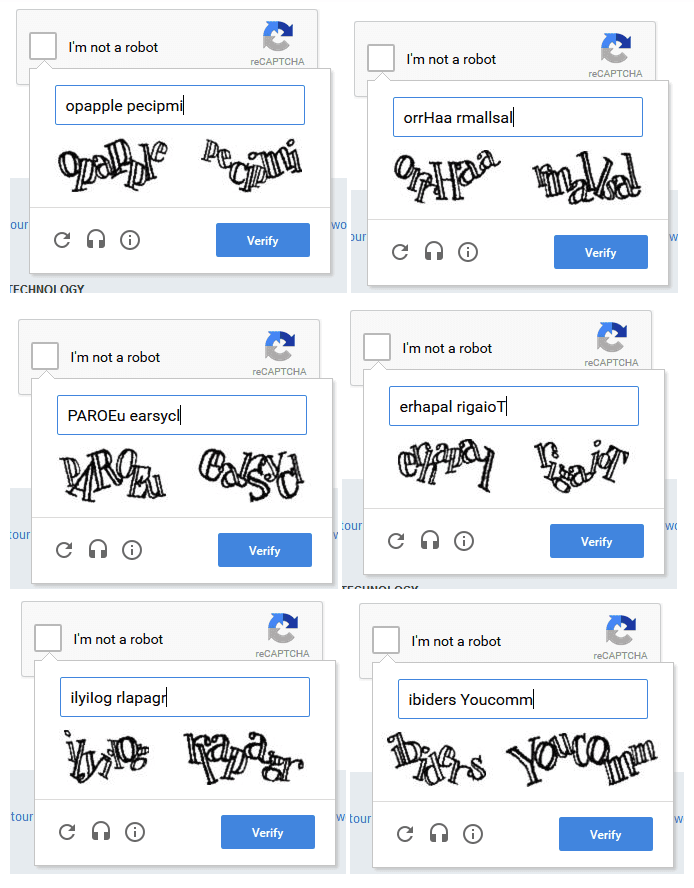

If you use the above services, on the other side of the API call, you will have hundreds of people who will solve the CAPTCHAs for very low costs. To do this, hire a freelancer on Fiverr at a lower cost may be a possible solution.
But again, even if you fix the CAPCHAs or change the proxy as soon as you see one, websites can still detect your data extraction process.
Another advanced tool used by websites to detect web scrapers is form recognition. Therefore, if you plan to scrape all e-commerce product identifiers from 1 to 10,000 for the URL www.siteweb.com/product/, try not to do it one after the other or with the number of requests per minute that is always constant.
For example, you can scrape a random number of products over a given period of time by randomizing the behavior of your data extraction.
Some websites also compile browser fingerprint statistics by access point. This means that if you don't change certain settings in your browser or its behavior, you could be blocked.
Websites also tend to monitor where traffic comes from. Therefore, if you want to scrape a website in Canada, try not to do it with proxies located in Germany.
But from experience, I can tell you that speed is the most important factor in “request recognition,” so the slower you scrape, the less likely you are to be discovered.
Sometimes the server expects the client to be a machine. In these cases, it is much easier to hide.
Broadly speaking, this “tip” comes down to two things:
For example, let's say I want to get all the feedback from a famous social network. I notice that when I click on the “load more comments” button, this happens in my inspector:
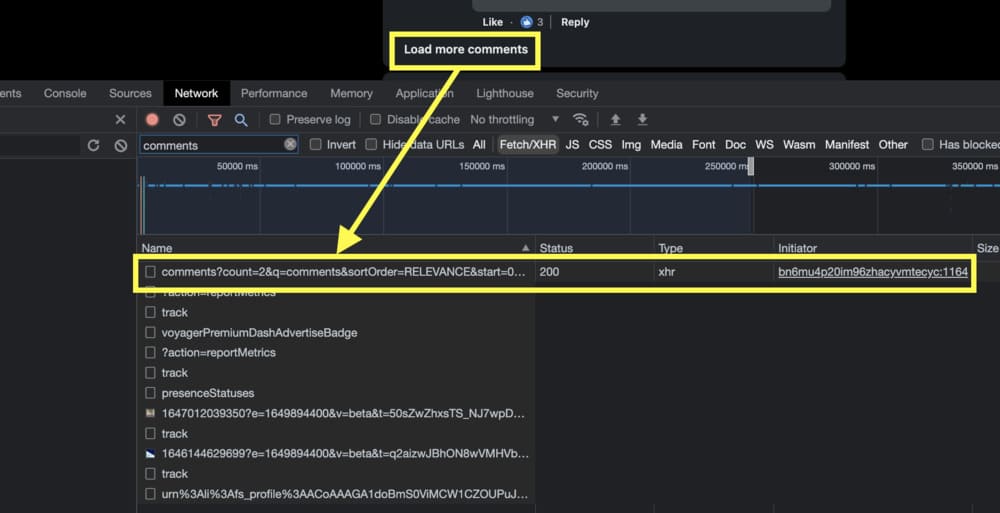
Note that we filter all requests, except for “XHR” requests, to avoid noise.
When we try to see what request is made and what response we get... - bingo!
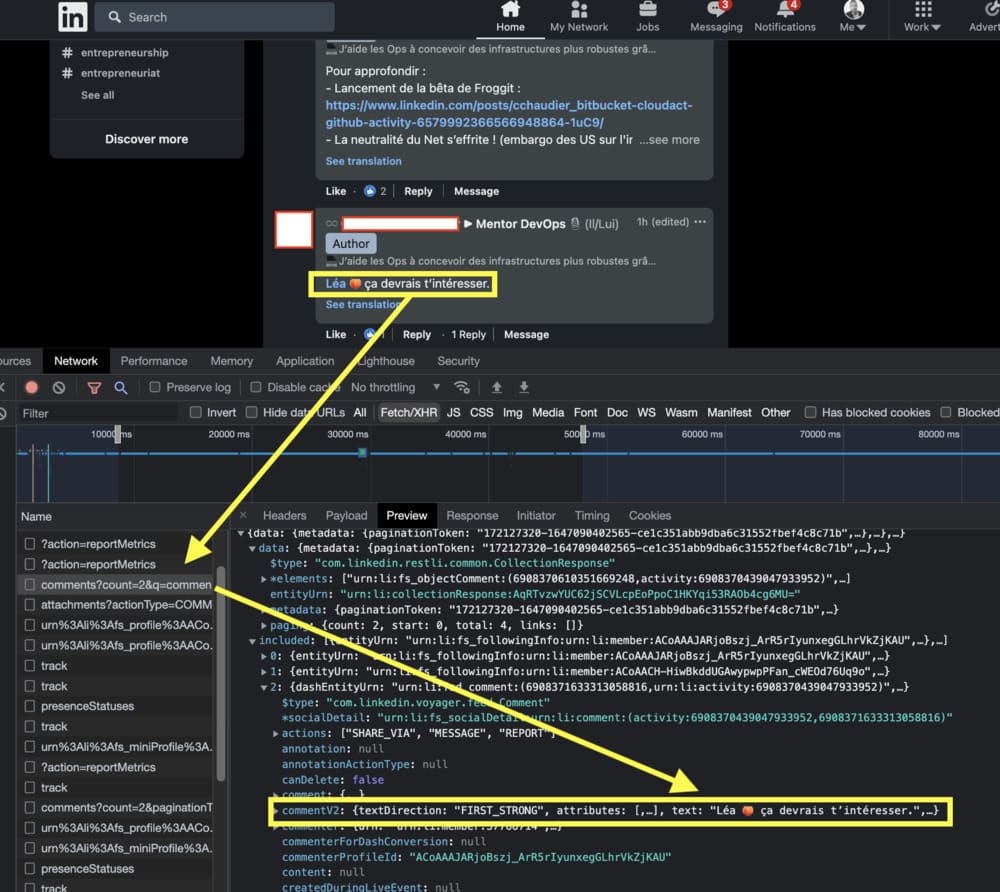
Right click on the item and export it (HAR file)

Now, if we look at the “Headers” tab, we should have everything we need to replay this request and understand the value of each parameter.
This will allow us to make this request from a simple HTTP client.
To do that, we're going to use our HAR file and then import it into a preferred HTTP client (PostMan for example).
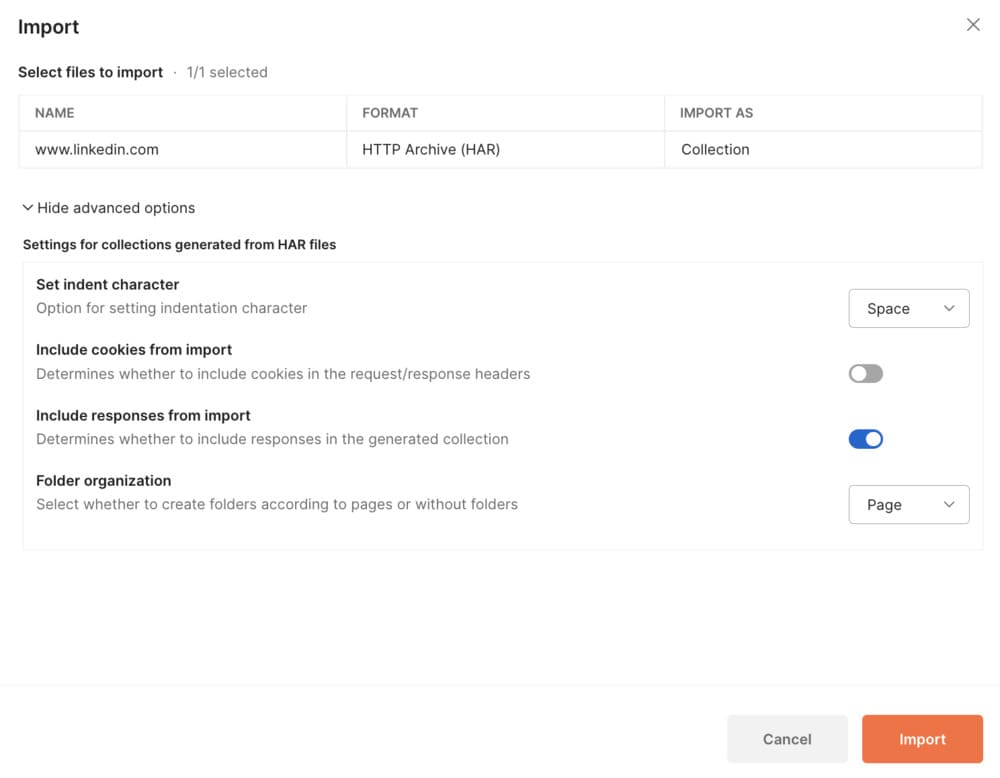
This will allow you to have all the parameters of a functional query and will make your experimentation much faster and more fun.

The same principles apply to reverse engineering a mobile application. You will want to intercept the request that your mobile application sends to the server and replay it with your code.
This task is difficult for 2 reasons:
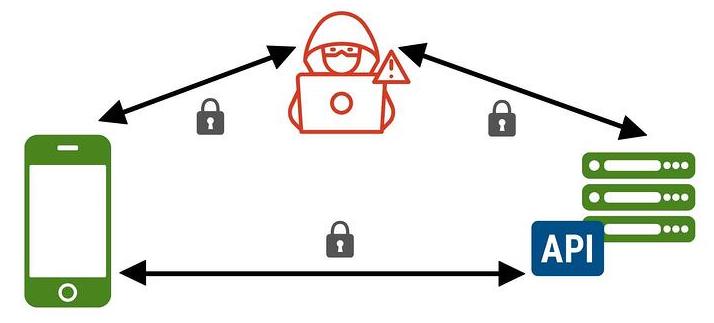
For example, when Pokemon Go was released a few years ago, tons of people cheated at the game after reverse engineering mobile app requests.
What they didn't know was that the mobile app was sending a “secret” parameter that wasn't sent by the cheat script. It was then easy to identify the cheaters.
A few weeks later, a large number of players were banned for cheating.
Here is also an interesting example of someone who reverse engineered theMacDonald API.
Here's a summary of all the anti-bot techniques we've seen in this article:
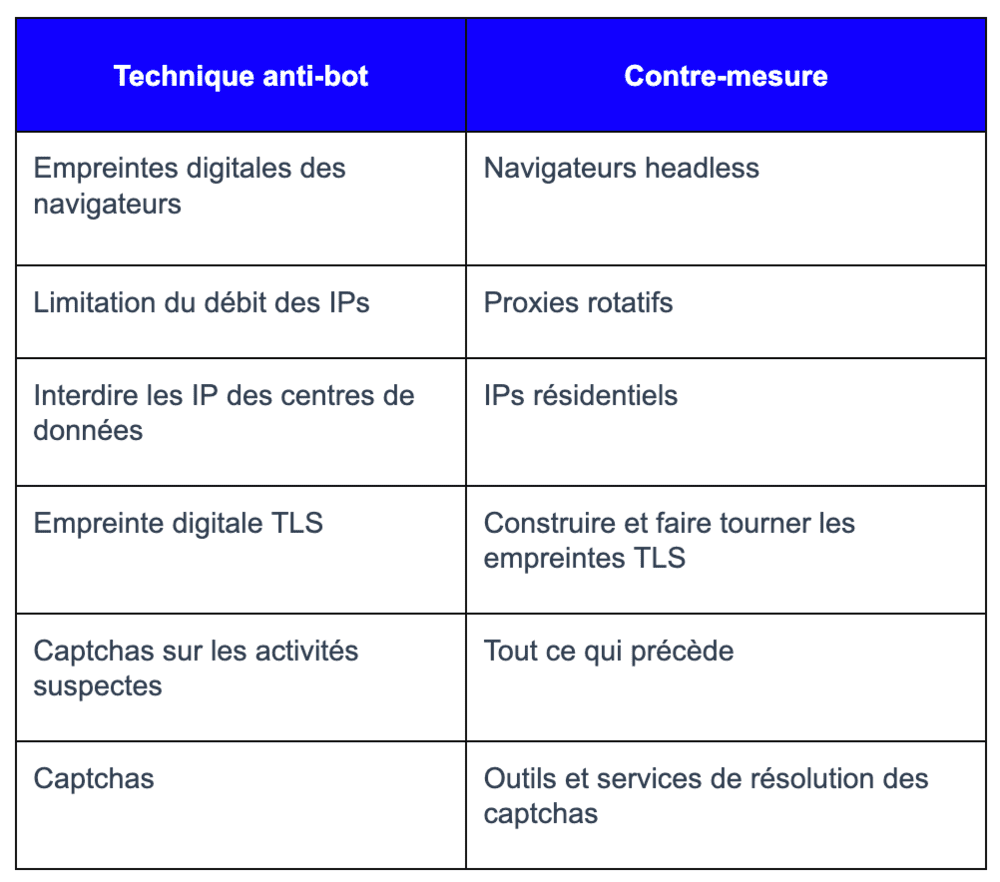
Hopefully this overview will help you understand Web Scraping and that you have learned a lot by reading this article.
Our web scraping API processes thousands of requests per second without ever being blocked. If you don't want to waste too much time setting up everything, feel free to try ScrapingBee. The first 1,000 API calls are for us:).
I've published a guide to the best web scraping tools of the market, do not hesitate to take a look at it!